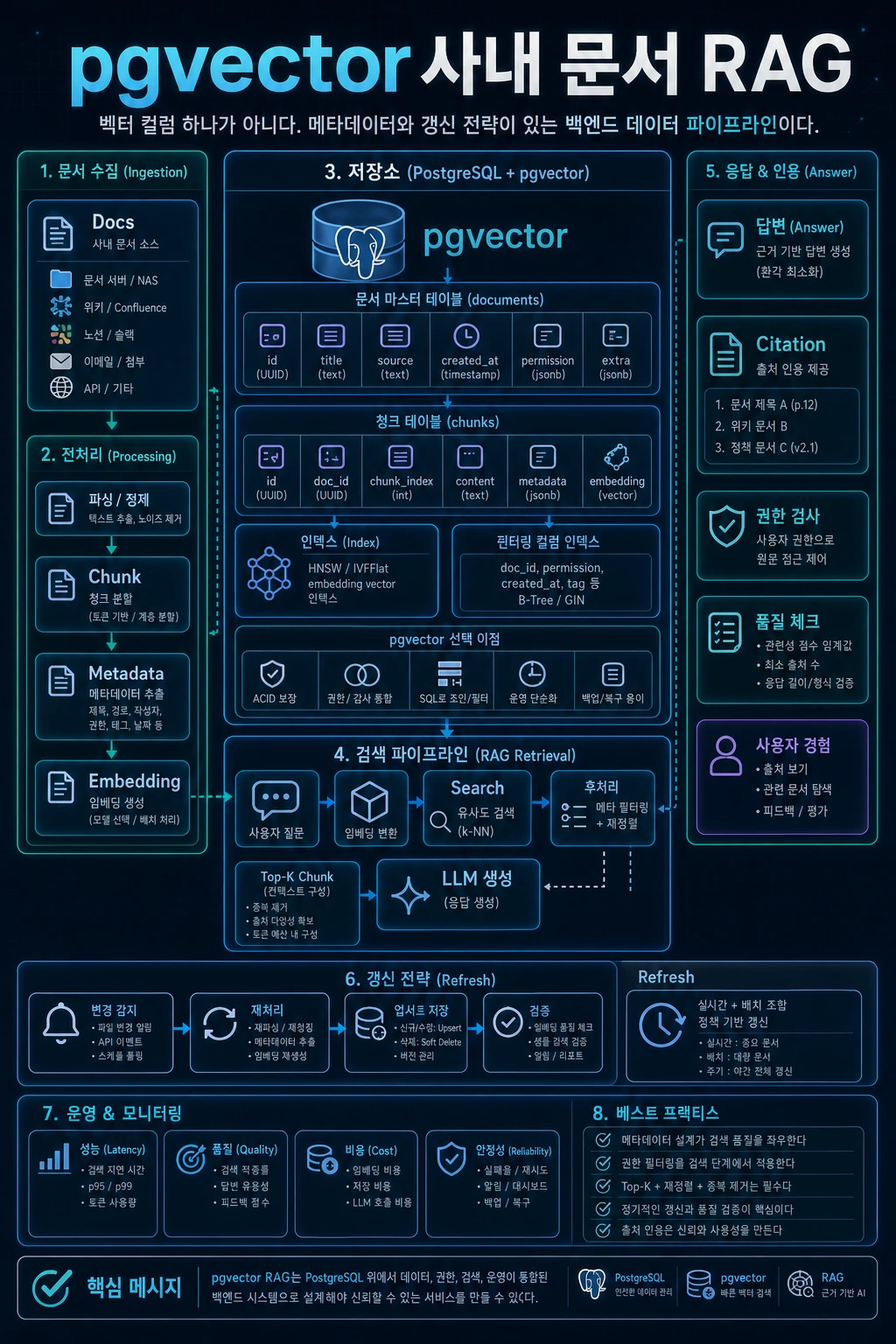
PostgreSQL 안에서 문서 chunk와 embedding 검색하기
이 글에서는 PostgreSQL과 pgvector를 사용해 문서형 RAG 서비스의 기본 검색 구조를 만들어봅니다.
전용 vector DB를 바로 도입할 수도 있지만, 학습과 초기 서비스에서는 PostgreSQL 안에서 벡터 검색을 시작하는 선택이 꽤 실용적입니다. 사용자, 문서, 질문 이력, 색인 상태를 이미 PostgreSQL에 저장한다면 embedding도 같은 DB에서 관리할 수 있기 때문입니다.
분석 기준일: 2026-05-12
실습 기준 환경: PostgreSQL 16+, pgvector, Python, FastAPI
주요 참고자료: pgvector GitHub, Supabase pgvector Docs, RAG Paper
핵심 요약
- pgvector는 PostgreSQL에서 vector similarity search를 가능하게 하는 확장이다.
- 문서형 RAG에서는
documents,document_chunks,embeddings,index_jobs테이블이 기본이다. - 검색 쿼리는 vector similarity뿐 아니라 metadata filter와 권한 조건을 함께 적용해야 한다.
- chunk_id는 citation과 eval에 연결되는 핵심 식별자다.
- 초기에는 exact search로 시작하고, 데이터가 커지면 index 전략을 검토한다.
1. 왜 pgvector인가
pgvector의 장점은 운영 단순성입니다.
| 선택지 | 장점 | 주의점 |
|---|---|---|
| PostgreSQL + pgvector | 기존 DB와 함께 운영 가능 | 대규모 벡터 전용 최적화는 제한적 |
| 전용 vector DB | 대규모 검색 기능 풍부 | 별도 운영 복잡도 |
| 검색 엔진 + vector | hybrid search에 유리 | 학습 비용 증가 |
초기 학습 프로젝트에서는 pgvector가 좋습니다. SQL로 데이터 모델과 검색을 함께 이해할 수 있기 때문입니다.
2. RAG 데이터 모델
기본 테이블은 다음과 같습니다.
# 예시입니다.documents- id- title- source_type- source_url- version- created_at- updated_at document_chunks- id- document_id- chunk_index- content- token_count- metadata- embedding- created_at index_jobs- id- document_id- idempotency_key- status- error_code- created_at- updated_at3. pgvector 설치와 확장 활성화
/* 예시 SQL입니다. */CREATE EXTENSION IF NOT EXISTS vector;embedding 차원이 1536이라고 가정하면 다음처럼 컬럼을 만들 수 있습니다.
/* 예시 SQL입니다. */CREATE TABLE document_chunks ( id UUID PRIMARY KEY, document_id UUID NOT NULL, chunk_index INT NOT NULL, content TEXT NOT NULL, token_count INT NOT NULL, metadata JSONB NOT NULL DEFAULT '{}', embedding vector(1536), created_at TIMESTAMPTZ NOT NULL DEFAULT now());embedding 차원은 사용하는 embedding 모델에 맞춰야 합니다.
4. 문서와 chunk 테이블 설계
문서 원본과 chunk는 분리해야 합니다.
| 테이블 | 역할 |
|---|---|
documents | 문서 단위 metadata, version 관리 |
document_chunks | 검색 가능한 본문 조각 |
index_jobs | 색인 작업 상태 관리 |
questions | 사용자 질문 이력 |
answers | 모델 답변과 citation 저장 |
chunk에는 반드시 document_id, chunk_index, content, metadata, embedding이 있어야 합니다.
5. Embedding 저장
embedding 생성 흐름:
# 예시입니다.문서 업로드→ 텍스트 추출→ chunking→ embedding 생성→ document_chunks에 저장Python 예시:
# 예시 코드입니다.async def index_chunks(document_id: str, chunks: list[str]): for idx, content in enumerate(chunks): embedding = await create_embedding(content) await repo.insert_chunk( document_id=document_id, chunk_index=idx, content=content, embedding=embedding, )6. Similarity Search 쿼리
pgvector에서는 거리 연산자를 이용해 유사한 vector를 찾을 수 있습니다.
/* 예시 SQL입니다. */SELECT id, document_id, content, metadata, embedding <-> :query_embedding AS distanceFROM document_chunksORDER BY embedding <-> :query_embeddingLIMIT 5;거리 값이 낮을수록 더 가깝다는 의미입니다. 사용하는 거리 방식은 embedding 모델과 검색 전략에 맞춰 선택해야 합니다.
7. Metadata Filter와 권한
실서비스에서는 vector similarity만으로 검색하면 안 됩니다. 문서 권한과 범위를 필터링해야 합니다.
/* 예시 SQL입니다. */SELECT c.id, c.document_id, c.content, c.embedding <-> :query_embedding AS distanceFROM document_chunks cJOIN documents d ON d.id = c.document_idWHERE d.source_type = :source_type AND d.visibility = 'public'ORDER BY c.embedding <-> :query_embeddingLIMIT :limit;사용자별 권한이 있으면 ACL 테이블과 join해야 합니다.
8. Citation 연결
RAG 답변에서 citation을 제공하려면 chunk_id가 답변에 연결되어야 합니다.
// 예시 JSON 구조입니다.{ "answer": "Cache Aside는 캐시를 먼저 조회하고 miss 시 DB를 조회하는 패턴입니다.", "citations": [ { "document_id": "doc_123", "chunk_id": "chunk_456", "quote": "check Redis first, return cached data on a hit..." } ]}citation은 모델이 임의 생성하면 안 됩니다. 검색 결과로 제공된 chunk 목록에서만 선택하게 해야 합니다.
9. 운영 지표와 한계
| 지표 | 의미 |
|---|---|
retrieval_latency_ms | 검색 지연 |
retrieval_top_k | 검색 결과 수 |
retrieval_empty_result_count | 검색 실패 수 |
chunk_count_per_document | 문서별 chunk 수 |
embedding_generation_latency | embedding 생성 지연 |
index_job_failure_rate | 색인 실패율 |
pgvector는 초기 RAG 구현에 좋지만, 데이터가 커지고 검색 요구사항이 복잡해지면 전용 vector DB, hybrid search, reranker를 검토해야 합니다.
10. 실무 체크리스트
# 예시입니다.[ ] documents와 chunks를 분리했는가?[ ] document version을 저장하는가?[ ] chunk_id가 citation에 연결되는가?[ ] embedding model과 dimension을 기록하는가?[ ] metadata filter를 적용하는가?[ ] 사용자 권한이 retrieval 단계에서 강제되는가?[ ] 색인 job 상태를 추적하는가?[ ] 검색 실패 케이스를 eval dataset으로 저장하는가?실패 사례: 검색은 되지만 답변 근거를 설명하지 못하는 RAG
pgvector를 붙인 뒤 가장 먼저 만나는 실패는 "비슷한 문서는 찾았는데 답변 품질을 설명할 수 없는" 상태입니다. embedding column과 similarity query만 있으면 demo는 빠르게 됩니다. 사용자가 질문을 보내면 가까운 chunk를 가져오고, 모델은 그 chunk를 바탕으로 답합니다. 하지만 운영자가 "왜 이 문서를 골랐는가", "권한 없는 문서가 섞이지 않았는가", "답변에 사용된 chunk가 정확히 무엇인가"를 묻기 시작하면 단순 vector search는 부족합니다.
실패의 원인은 보통 metadata와 citation 설계가 늦게 들어가기 때문입니다. content와 embedding만 저장하면 검색은 가능하지만 문서 버전, tenant, 권한, source URL, chunk 순서, embedding model version을 추적할 수 없습니다. 나중에 hallucination 신고가 들어와도 어떤 chunk가 prompt에 들어갔는지 찾기 어렵습니다.
구현 예시: citation 중심 테이블 설계
RAG table은 답변 생성보다 감사 가능성을 먼저 고려해야 합니다.
create table document_chunks ( id uuid primary key, document_id uuid not null, tenant_id text not null, source_url text, chunk_index integer not null, content text not null, content_hash text not null, embedding_model text not null, embedding vector(1536), created_at timestamptz not null default now()); create index document_chunks_tenant_idx on document_chunks (tenant_id, document_id);검색 쿼리도 similarity만 보지 말고 tenant와 문서 상태를 함께 걸어야 합니다.
select id, document_id, source_url, chunk_index, contentfrom document_chunkswhere tenant_id = $1order by embedding <=> $2limit 8;이 예시는 단순하지만 두 가지 가치를 더합니다. 첫째, 답변에 사용한 chunk id를 그대로 citation으로 남길 수 있습니다. 둘째, 권한 조건을 vector search 바깥이 아니라 같은 query 안에 넣습니다. 실제 서비스에서는 문서 공개 범위, 삭제 상태, 최신 버전 여부도 filter에 포함해야 합니다.
체크리스트 적용 결과
| 항목 | 확인 질문 | 운영상 의미 |
|---|---|---|
| 권한 | tenant와 ACL filter가 검색 query에 포함되는가 | 내부 문서 노출 방지 |
| 버전 | embedding model과 content hash를 저장하는가 | 재색인 필요 여부 판단 |
| citation | chunk id와 source URL을 답변 로그에 남기는가 | 신고와 eval 재현 |
| 품질 | top-k, threshold, rerank 결과를 측정하는가 | 검색 품질 개선 |
이 표를 통과하면 "pgvector를 붙였다"에서 "문서형 RAG 서비스를 운영할 수 있다"로 한 단계 올라갑니다.
운영 비교: pgvector만 볼 때와 RAG 제품으로 볼 때
pgvector 도입 판단은 검색 엔진 선택으로 끝나지 않습니다. 실제 제품에서는 "가까운 벡터를 찾는다"보다 "사용자가 볼 수 있는 문서 안에서, 설명 가능한 근거를, 제한 시간 안에 찾는다"가 더 중요합니다.
| 관점 | 단순 pgvector 데모 | 운영형 문서 RAG |
|---|---|---|
| 검색 조건 | embedding distance 기준 | 권한, 문서 상태, 버전, distance 결합 |
| 결과 저장 | 답변 텍스트만 저장 | answer, chunk_id, source_url, trace_id 저장 |
| 실패 대응 | 결과 없음 메시지 | 빈 결과, 낮은 confidence, 재색인 필요 분리 |
| 품질 개선 | prompt 수정 | retrieval eval, chunk 정책, reranker 비교 |
예를 들어 사내 규정 문서 RAG에서 사용자가 "휴가 이월 기준"을 묻는다고 해봅시다. vector search는 비슷한 문단을 찾을 수 있지만, 문서가 폐기된 이전 규정이면 답변에 쓰면 안 됩니다. 따라서 documents.status = 'active', documents.effective_from <= now(), tenant_id = current_tenant 같은 조건이 similarity query와 함께 적용되어야 합니다. 답변 로그에는 사용된 chunk_id와 document.version을 남겨야 이후 규정 변경 시 어떤 답변이 낡았는지도 찾을 수 있습니다.
반대로 실패 사례는 metadata filter를 나중에 붙이는 경우입니다. 처음에는 모든 문서를 한 테이블에 넣고 잘 검색되는지 확인합니다. 이후 권한이 생기면 application layer에서 검색 결과를 필터링하려고 합니다. 이 방식은 top-k가 이미 권한 없는 문서로 채워진 뒤라, 필터 후 결과가 비어버릴 수 있습니다. 권한 조건은 검색 이후가 아니라 후보를 고르는 query 자체에 들어가야 합니다. 그래야 "검색은 잘 됐는데 사용자는 아무 답도 못 받는" 상황을 줄일 수 있습니다.
11. Q&A
Q1. pgvector만으로 충분한가요?
초기 학습과 작은 서비스에는 충분할 수 있습니다. 하지만 대규모 검색, 복잡한 hybrid search, 고성능 요구사항이 생기면 별도 검색 엔진이나 vector DB를 검토해야 합니다.
Q2. chunk 크기는 얼마가 적당한가요?
정답은 없습니다. 문서 유형, 질문 패턴, embedding 모델에 따라 다릅니다. 보통 여러 크기를 실험하고 retrieval eval로 비교해야 합니다.
Q3. embedding 모델을 바꾸면 어떻게 하나요?
기존 embedding과 차원이 다르거나 의미 공간이 다르면 재색인이 필요합니다. embedding_model_version을 반드시 저장해야 합니다.
12. 참고자료와 불확실성
참고자료
- pgvector GitHub: https://github.com/pgvector/pgvector
- Supabase pgvector Docs: https://supabase.com/docs/guides/database/extensions/pgvector
- RAG Paper: https://arxiv.org/abs/2005.11401
불확실성
- embedding 차원과 거리 연산자는 사용하는 모델에 따라 달라집니다.
- 인덱스 전략은 데이터 크기와 latency 요구사항에 따라 실험이 필요합니다.
Retrieving document chunks and embeddings in PostgreSQL
In this article, we will create a basic search structure for a document-type RAG service using PostgreSQL and pgvector.
Although it is possible to adopt a dedicated vector DB right away, for training and initial service, the choice to start vector search within PostgreSQL is quite practical. This is because if users, documents, question history, and index status are already stored in PostgreSQL, embeddings can also be managed in the same DB.
Analysis base date: 2026-05-12 Practice environment: PostgreSQL 16+, pgvector, Python, FastAPI Main reference materials: pgvector GitHub, Supabase pgvector Docs, RAG Paper
Key takeaways
- pgvector is an extension that enables vector similarity search in PostgreSQL.
- In document type RAG, the tables
documents,document_chunks,embeddings, andindex_jobsare basic. - Search queries must apply not only vector similarity but also metadata filters and permission conditions.
- chunk_id is a key identifier linked to citation and eval.
- Initially, we start with an exact search, and as the data grows, we review the index strategy.
1. Why pgvector
The advantage of pgvector is its operational simplicity.
| Choice | merit | Things to note |
|---|---|---|
| PostgreSQL + pgvector | Can be operated with existing DB | Large-scale vector-only optimization is limited |
| Dedicated vector DB | Rich large-scale search capabilities | Separate operational complexity |
| search engine + vector | Advantageous for hybrid search | Increased learning costs |
For initial learning projects, pgvector is good. This is because you can understand the data model and search together with SQL.
2. RAG data model
The basic table is as follows:
# This is an example.documents- id- title- source_type- source_url- version- created_at- updated_at document_chunks- id- document_id- chunk_index- content- token_count- metadata- embedding- created_at index_jobs- id- document_id- idempotency_key- status- error_code- created_at- updated_at3. Install pgvector and activate extension
/* This is example SQL.*/CREATE EXTENSION IF NOT EXISTS vector;Assuming the embedding dimension is 1536, you can create a column like this:
/* This is example SQL.*/CREATE TABLE document_chunks ( id UUID PRIMARY KEY, document_id UUID NOT NULL, chunk_index INT NOT NULL, content TEXT NOT NULL, token_count INT NOT NULL, metadata JSONB NOT NULL DEFAULT '{}', embedding vector(1536), created_at TIMESTAMPTZ NOT NULL DEFAULT now());The embedding dimension should match the embedding model you use.
4. Document and chunk table design
The original document and chunk must be separated.
| table | role |
|---|---|
documents | Document-level metadata and version management |
document_chunks | Searchable body fragments |
index_jobs | Manage index operation status |
questions | User question history |
answers | Save model answers and citations |
The chunk must containdocument_id,chunk_index,content,metadata, andembedding.
5. Save Embedding
Embedding creation flow:
# This is an example.Upload documentto text extraction→ chunkingto create embeddingSave to document_chunksPython example:
# This is example code.async def index_chunks(document_id: str, chunks: list[str]): for idx, content in enumerate(chunks): embedding = await create_embedding(content) await repo.insert_chunk( document_id=document_id, chunk_index=idx, content=content, embedding=embedding, )6. Similarity Search query
In pgvector, you can find similar vectors using the distance operator.
/* This is example SQL.*/SELECT id, document_id, content, metadata, embedding <-> :query_embedding AS distanceFROM document_chunksORDER BY embedding <-> :query_embeddingLIMIT 5;A lower distance value means closer. The distance method used should be selected according to the embedding model and search strategy.
7. metadata filter and Permissions
In actual services, you should not search for vector similarity alone. You need to filter document permissions and scope.
/* This is example SQL.*/SELECT c.id, c.document_id, c.content, c.embedding <-> :query_embedding AS distanceFROM document_chunks cJOIN documents d ON d.id = c.document_idWHERE d.source_type = :source_type AND d.visibility = 'public'ORDER BY c.embedding <-> :query_embeddingLIMIT :limit;If there are user-specific permissions, they must be joined with the ACL table.
8. Citation connection
To provide a citation in a RAG answer, a chunk_id must be associated with the answer.
// This is an example JSON structure.{ "answer": "Cache Aside is a pattern that searches the cache first and then searches the DB when there is a miss.", "citations": [ { "document_id": "doc_123", "chunk_id": "chunk_456", "quote": "check Redis first, return cached data on a hit..." } ]}Citations should not be randomly generated by the model. You should only select from the list of chunks provided as search results.
9. Operational indicators and limitations
| characteristic | meaning |
|---|---|
retrieval_latency_ms | retrieval delay |
retrieval_top_k | Number of search results |
retrieval_empty_result_count | Number of search failures |
chunk_count_per_document | Number of chunks per document |
embedding_generation_latency | Embedding creation delay |
index_job_failure_rate | Index failure rate |
pgvector is good for initial RAG implementation, but as the data grows and search requirements become more complex, you should consider a dedicated vector DB, hybrid search, or reranker.
10. Practical checklist
# This is an example.[ ] Have you separated documents and chunks?[ ] Do you save the document version?[ ] Is chunk_id connected to citation?[ ] Are the embedding model and dimensions recorded?[ ] Do you apply metadata filter?[ ] Are user rights enforced during the retrieval step?[ ] Do you track index job status?[ ] Are search failure cases saved as eval dataset?Failure example: RAG that searches but fails to explain the basis for the answer
The first failure you encounter after attaching pgvector is the situation of “Similar documents were found, but the quality of the answer cannot be explained.” All you need is an embedding column and a similarity query to create a demo quickly. When a user sends a question, the nearby chunk is retrieved, and the model answers based on that chunk. However, when operators start asking “Why did you pick this document?”, “Are there any unauthorized documents mixed in?”, or “What exactly is the chunk used in the answer?”, a simple vector search falls short.
The cause of failure is usually the late entry of metadata and citation design. If you only savecontentandembedding, you can search, but you cannot track document version, tenant, permission, source URL, chunk order, and embedding model version. Even if a hallucination report comes in later, it is difficult to find which chunk entered the prompt.
Implementation example: citation-driven table design
The RAG table must consider auditability before answer generation.
create table document_chunks ( id uuid primary key, document_id uuid not null, tenant_id text not null, source_url text, chunk_index integer not null, content text not null, content_hash text not null, embedding_model text not null, embedding vector(1536), created_at timestamptz not null default now()); create index document_chunks_tenant_idx on document_chunks (tenant_id, document_id);Search queries should not only look at similarity, but also consider tenant and document status.
select id, document_id, source_url, chunk_index, contentfrom document_chunkswhere tenant_id = $1order by embedding <=> $2limit 8;This example is simple, but adds two values. First, you can leave the chunk id you used in your answer as a citation. Second, put the permission conditions within the same query, not outside the vector search. In an actual service, the document disclosure scope, deletion status, and latest version should also be included in the filter.
Checklist application results
| item | confirmation question | Operational implications |
|---|---|---|
| authority | Are tenants and ACL filters included in the search query? | Prevent exposure of internal documents |
| version | Do you store the embedding model and content hash? | Determine whether reindex is necessary |
| citation | Do you leave chunk id and source URL in the response log? | Report and eval reproduction |
| quality | Do you measure top-k, threshold, and rerank results? | Improve search quality |
If you pass this table, you go up one level from “pgvector attached” to “can operate document-type RAG service.”
Operational comparison: pgvector alone vs. RAG product
The decision to adopt pgvector does not end with search engine selection. In actual products, it is more important to “find explanatory evidence within a document visible to the user, within a time limit” than to “find a nearby vector.”
| aspect | Simple pgvector demo | Operational document RAG |
|---|---|---|
| Search criteria | Based on embedding distance | Combining permissions, document status, version, and distance |
| Save results | Save only the answer text | Save answer, chunk_id, source_url, trace_id |
| response to failure | No results message | Isolate empty results, low confidence, need to reindex |
| quality improvement | Edit prompt | retrieval eval, chunk policy, reranker comparison |
For example, in your company policy document RAG, let's say a user asks "vacation carryover criteria." A vector search can find similar paragraphs, but if the document is an obsolete old regulation, you should not use it in your answer. Therefore, conditions such asdocuments.status = 'active',documents.effective_from <= now(), andtenant_id = current_tenantmust be applied together with the similarity query. You should leave the usedchunk_idanddocument.versionin the answer log so that you can find out which answers are outdated when the regulations change in the future.
Conversely, a failure case is when a metadata filter is added later. First, put all your documents in one table and see if they are searchable. After gaining permission, we try to filter the search results at the application layer. This method may result in empty results after filtering, since top-k is already filled with unauthorized documents. Permission conditions must be included in the query itself to select candidates, not after the search. This will reduce situations where “the search is successful, but the user does not receive any response.”
11. Q&A
Q1. Is pgvector alone enough?
This may be sufficient for initial learning and small services. However, when large-scale searches, complex hybrid searches, and high-performance requirements arise, a separate search engine or vector DB must be considered.
Q2. What is the appropriate chunk size?
There is no right answer. It depends on the document type, question pattern, and embedding model. Usually you need to experiment with different sizes and compare them with retrieval eval.
Q3. What if I change the embedding model?
If the dimension or semantic space is different from the existing embedding, re-indexing is required. You must save embedding_model_version.
12. References and uncertainty
References
- pgvector GitHub:https://github.com/pgvector/pgvector
- Supabase pgvector Docs:https://supabase.com/docs/guides/database/extensions/pgvector
- RAG Paper:https://arxiv.org/abs/2005.11401
uncertainty
- The embedding dimension and distance operator depend on the model you use.
- Index strategies require experimentation depending on data size and latency requirements.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.