API, RAG, 모델 서빙, 평가, 관측성까지
이 글에서는 LLM 서비스를 단순한 실험 단계에서 운영 가능한 백엔드 시스템으로 끌어올리기 위해 어떤 순서로 공부해야 하는지 정리합니다.
요즘은 LLM 기능을 빠르게 붙일 수 있는 도구가 많습니다. API를 한 번 호출하면 답변이 나오고, 프레임워크를 쓰면 RAG나 Agent도 비교적 빠르게 만들 수 있습니다. 하지만 실서비스로 들어가면 질문이 바뀝니다.
“답변이 나온다”보다 중요한 것은 “장애가 나도 버틸 수 있는가”입니다.
“모델이 똑똑하다”보다 중요한 것은 “비용, 지연, 품질을 측정할 수 있는가”입니다.
“데모가 된다”보다 중요한 것은 “팀이 같은 기준으로 운영하고 개선할 수 있는가”입니다.
분석 기준일: 2026-05-12
실습 기준 환경: Python 3.12, FastAPI, PostgreSQL, Redis, Docker Compose
주요 참고자료: OpenAI API Docs, Redis Docs, AWS Builders Library, RAG Paper, pgvector, OpenTelemetry Docs
핵심 요약
- LLM 서비스는 모델 호출보다 백엔드 운영 기본기에서 먼저 무너진다.
- 학습 순서는
프로덕션 백엔드 → LLM 애플리케이션 계층 → RAG/워크플로우 → 모델 서빙 → Evals/Observability가 적절하다. - 하나의 실습 프로젝트를 단계적으로 고도화하면 설계 결정, 구현, 측정 기준을 한 흐름으로 검증할 수 있다.
- 공식문서, 논문, 기업기술블로그는 각각 읽는 목적이 다르다.
- 각 단계는 구현, 측정, 체크리스트로 검증 가능해야 한다.
1. PoC와 프로덕션의 차이
PoC는 가능성을 확인하는 단계입니다. 그래서 가장 중요한 목표는 빠른 검증입니다. 사용자가 질문을 입력하고, 모델이 답변하고, 데모 화면에서 흐름이 보이면 충분할 수 있습니다.
반면 프로덕션은 다릅니다. 프로덕션은 실패를 전제로 설계해야 합니다. 외부 모델 API가 느려질 수 있고, rate limit에 걸릴 수 있고, Redis가 내려갈 수 있고, 잘못된 프롬프트 변경으로 품질이 떨어질 수 있습니다.
| 구분 | PoC | Production |
|---|---|---|
| 목표 | 가능성 검증 | 안정적 운영 |
| 모델 호출 | 직접 호출 | Gateway, retry, fallback, timeout |
| 데이터 | 샘플 문서 | 권한, 버전, 색인 상태 관리 |
| 품질 | 사람이 눈으로 확인 | Evals, golden set, 회귀 테스트 |
| 운영 | 로그 확인 정도 | traces, metrics, logs, alert |
| 배포 | 수동 변경 | canary, rollback, release note |
결국 프로덕션 전환은 기능 추가가 아니라 운영 조건을 받아들이는 과정입니다.
2. 왜 LLM보다 백엔드 기본기가 먼저인가
LLM 기능은 단독으로 존재하지 않습니다. 실제 서비스 안에서는 사용자, 인증, 문서, 결제, 권한, 로그, 캐시, 큐, 알림, 모니터링과 연결됩니다.
예를 들어 문서 Q&A 서비스를 만든다고 가정해보겠습니다. 사용자는 질문을 하고, 서버는 관련 문서를 검색하고, 검색 결과를 프롬프트에 넣고, 모델을 호출하고, 답변을 저장하고, 출처를 보여줍니다. 이 과정에서 필요한 것은 단순한 프롬프트가 아닙니다.
# 예시입니다.사용자 요청→ API validation→ 인증/권한 확인→ 문서 검색→ LLM 호출→ 응답 검증→ 결과 저장→ 비용/지연 로깅→ trace 연결→ eval 데이터 축적이 흐름에서 백엔드 기본기가 약하면 LLM은 오히려 장애를 키우는 계층이 됩니다.
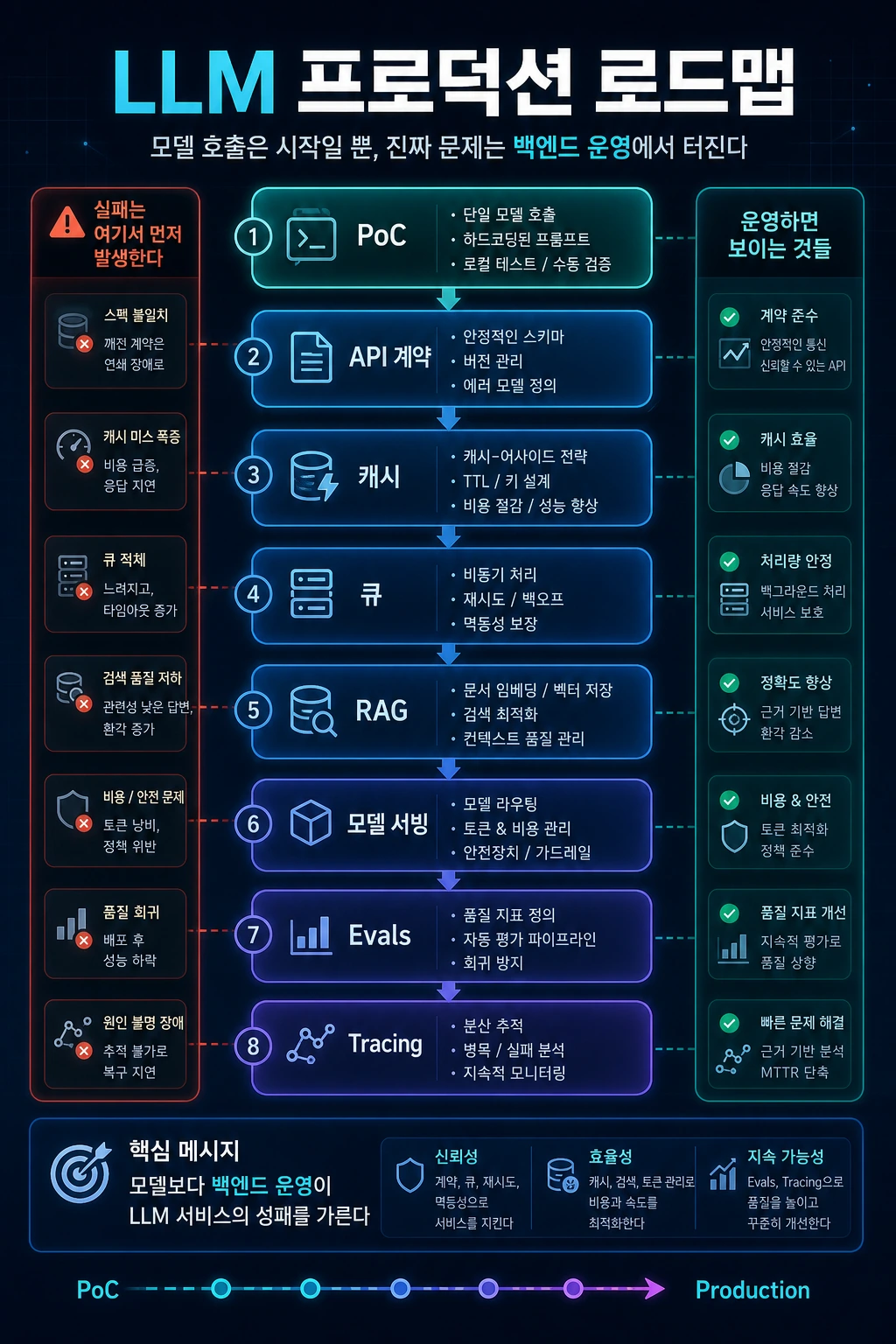
3. 전체 학습 순서
추천하는 학습 순서는 아래와 같습니다.
| 단계 | 학습 영역 | 핵심 질문 | 대표 산출물 |
|---|---|---|---|
| 1 | Production Backend | 서비스가 장애와 트래픽을 견딜 수 있는가? | API, DB, Redis, Queue, 로그 |
| 2 | LLM Application Layer | 모델 출력을 서비스 계약으로 다룰 수 있는가? | Structured Outputs, Function Calling |
| 3 | RAG & Workflow | 외부 지식을 근거 기반 답변으로 연결할 수 있는가? | 문서 색인, pgvector, 재색인 큐 |
| 4 | Serving & Traffic | 지연, 처리량, 비용을 측정하고 줄일 수 있는가? | Gateway, load test, autoscaling |
| 5 | Evals & Observability | 품질과 장애를 데이터로 설명할 수 있는가? | golden set, trace, dashboard |
| 6 | Engineering Leadership | 팀이 같은 기준으로 개발할 수 있는가? | ADR, code review checklist, runbook |
이 순서는 기술 유행이 아니라 의존성 순서입니다. API와 데이터 구조가 없으면 RAG를 운영할 수 없고, Evals가 없으면 프롬프트 변경을 안전하게 배포할 수 없습니다.
4. 실습 프로젝트 설계
이 시리즈에서는 하나의 프로젝트를 계속 고도화합니다.
# 예시입니다.Production-grade LLM Document Q&A Service목표는 공식문서, 논문, 기술블로그, 사내 문서와 비슷한 문서를 색인하고, 사용자의 질문에 근거 기반 답변을 제공하는 백엔드 시스템을 만드는 것입니다.
| 레이어 | 초기 구현 | 고도화 방향 |
|---|---|---|
| API | 질문 생성/조회 API | 실패 응답, trace ID, rate limit |
| DB | 사용자, 문서, 질문 이력 | 색인 상태, prompt version, eval result |
| Cache | Redis response cache | token budget, prompt hash, TTL 정책 |
| Queue | 문서 색인 작업 | idempotency, retry, DLQ |
| RAG | pgvector 검색 | reranking, citation, quality eval |
| LLM | 외부 API 호출 | provider routing, timeout, fallback |
| Observability | structured log | trace, metrics, dashboard |
| Quality | 수동 확인 | golden set, regression test |
5. 각 단계별 학습 주제
초기 12편은 전체 로드맵의 MVP입니다.
| 순서 | 글 제목 | 목적 |
|---|---|---|
| 1 | LLM 서비스를 PoC에서 프로덕션으로 끌어올리는 백엔드 로드맵 | 전체 방향 설정 |
| 2 | LLM보다 백엔드 기본기가 먼저인 이유 | 학습 순서 설득 |
| 3 | 운영 가능한 API 설계 | API 계약과 추적성 |
| 4 | Redis Cache Aside로 LLM 응답 캐시 설계하기 | 비용·지연 최적화 기초 |
| 5 | Queue와 Idempotency | 긴 작업과 재시도 안정화 |
| 6 | Structured Outputs 실전 | 모델 출력을 계약으로 다루기 |
| 7 | Function Calling 설계 | LLM과 내부 API 경계 |
| 8 | Prompt Caching과 Token Budget | 비용과 지연 운영 지표화 |
| 9 | RAG 논문 백엔드 관점으로 읽기 | 이론의 실무 해석 |
| 10 | pgvector로 문서형 RAG 서비스 만들기 | 구현 중심 RAG |
| 11 | LLM Evals 입문 | 품질 회귀 테스트 |
| 12 | OpenTelemetry로 LLM 요청 Trace 연결하기 | 관측성 설계 |
6. 자료 읽는 법
공식문서, 논문, 기업기술블로그는 같은 방식으로 읽으면 안 됩니다.
| 자료 | 읽는 목적 | 실습 산출물 |
|---|---|---|
| 공식문서 | API 계약, 제한, 설정값 확인 | 사용 조건, 주의사항, 코드 예제 |
| 논문 | 문제 정의와 핵심 아이디어 이해 | 백엔드 구조로 재해석한 그림 |
| 기업기술블로그 | 실무 제약과 트레이드오프 학습 | 내 프로젝트에 적용할 체크리스트 |
7. 실무 체크리스트
# 예시입니다.[ ] 이 단계는 하나의 운영 문제를 다루는가?[ ] 공식 자료에서 확인한 사실과 내 해석을 분리했는가?[ ] 구현 또는 실험 산출물이 있는가?[ ] 비용, 지연, 안정성 중 하나 이상을 측정했는가?[ ] 다른 개발자가 따라 할 수 있는 체크리스트가 있는가?[ ] 다음 글과 연결되는 학습 흐름이 있는가?8. Q&A
Q1. LangChain이나 Agent 프레임워크부터 공부하면 안 되나요?
공부해도 됩니다. 다만 먼저 붙잡을 주제로는 적합하지 않습니다. 프레임워크는 구현을 빠르게 해주지만, 장애 대응, 비용 추적, 데이터 모델, 평가 기준을 대신 설계해주지는 않습니다.
Q2. 자체 모델 서빙도 바로 공부해야 하나요?
초기에는 외부 API를 안정적으로 붙이는 경험이 더 중요합니다. 자체 서빙은 GPU, batching, autoscaling, observability가 함께 필요한 고급 주제입니다.
Q3. 이 시리즈의 최종 산출물은 무엇인가요?
최종 산출물은 문서 Q&A 서비스 하나가 아니라, 그 서비스를 운영 가능한 구조로 고도화한 설계 기록입니다. 코드보다 중요한 것은 의사결정과 운영 기준입니다.
9. 참고자료와 불확실성
참고자료
- OpenAI Structured Outputs Docs: https://platform.openai.com/docs/guides/structured-outputs
- OpenAI Function Calling Docs: https://platform.openai.com/docs/guides/function-calling
- OpenAI Evals Docs: https://platform.openai.com/docs/guides/evals
- Redis Cache Aside Tutorial: https://redis.io/tutorials/howtos/solutions/microservices/caching/
- AWS Builders Library — Idempotent APIs: https://aws.amazon.com/builders-library/making-retries-safe-with-idempotent-APIs/
- RAG Paper: https://arxiv.org/abs/2005.11401
- pgvector: https://github.com/pgvector/pgvector
- OpenTelemetry Docs: https://opentelemetry.io/docs/
불확실성
- OpenAI API 기능과 가격은 모델과 시점에 따라 바뀔 수 있습니다.
- 자체 모델 서빙은 GPU 환경, 모델 크기, 배포 방식에 따라 결과가 크게 달라집니다.
- 이 글의 실습 환경은 학습용 기준이며 실제 조직 환경에서는 보안, 권한, 비용 정책을 별도로 반영해야 합니다.
API, RAG, model serving, evaluation, and observability
In this article, we outline the order in which you should study to elevate your LLM service from a simple experimental stage to an operational back-end system.
These days, there are many tools that allow you to quickly attach LLM features. You can get an answer by calling the API once, and if you use a framework, you can create a RAG or Agent relatively quickly. But once you get into actual service, the questions change.
What is more important than “the answer will come” is “can you persevere even if you have a disability?” More important than “is the model smart” is “can you measure cost, delay, and quality?” What is more important than “it’s a demonstration” is “can the team operate and improve with the same standards?”
Analysis date: 2026-05-12 Lab standard environment: Python 3.12, FastAPI, PostgreSQL, Redis, Docker Compose Key references: OpenAI API Docs, Redis Docs, AWS Builders Library, RAG Paper, pgvector, OpenTelemetry Docs
Key takeaways
- The LLM service breaks down in the basics of backend operation rather than model calls.
- The appropriate learning order is
production backend to LLM application layer to RAG/workflow to model serving to Evals/observability. - By advancing one practice project step by step, design decisions, implementation, and measurement criteria can be verified in one flow.
- Official documents, papers, and corporate technology blogs each have different reading purposes.
- Each step must be implementable, measurable, and verifiable with a checklist.
1. Difference between PoC and production
PoC is the step to confirm feasibility. So the most important goal is fast verification. It may be enough for the user to enter a question, the model to answer, and the flow to be visible on the demo screen.
Production, on the other hand, is different. Production must be designed for failure. External model APIs can be slow, rate limits can be hit, Redis can crash, and quality can drop due to incorrect prompt changes.
| division | PoC | Production |
|---|---|---|
| target | feasibility verification | stable operation |
| model call | direct call | Gateway, retry, fallback, timeout |
| data | sample document | Manage permissions, versions, and index status |
| quality | A person can see with his or her eyes | Evals, golden sets, regression tests |
| operate | Log confirmation level | traces, metrics, logs, alert |
| distribution | manual change | canary, rollback, release note |
Ultimately, transitioning to production is a process of accepting operating conditions, not adding features.
2. Why backend basics come before LLM
The LLM feature does not exist in isolation. Within the actual service, it is connected to users, authentication, documents, payments, permissions, logs, caches, queues, notifications, and monitoring.
For example, let's say you're creating a document Q&A service. The user asks a question, the server retrieves relevant documents, puts the search results into a prompt, calls the model, stores the answer, and shows the source. This process requires more than just prompts.
# This is an example.user request→ API validationto authentication/authorization checkto document searchto LLM callto response verificationto save resultsto cost/delay loggingto trace connectionto eval data accumulationIn this flow, if the backend basics are weak, LLM becomes a layer that increases obstacles.
3. Entire learning sequence
The recommended learning sequence is as follows.
| step | study area | key questions | representative output |
|---|---|---|---|
| 1 | Production Backend | Can the service withstand failures and traffic? | API, DB, Redis, Queue, Log |
| 2 | LLM Application Layer | Can model output be treated as a service contract? | Structured Outputs, function calling |
| 3 | RAG & Workflow | Can we connect external knowledge to evidence-based answers? | Document index, pgvector, reindex queue |
| 4 | Serving & Traffic | Can delays, throughput, and costs be measured and reduced? | Gateway, load test, autoscaling |
| 5 | Evals & observability | Can quality and failure be explained by data? | golden set, trace, dashboard |
| 6 | Engineering Leadership | Can the teams develop to the same standards? | ADR, code review checklist, runbook |
This order is not a technology fad, but a dependency order. Without APIs and data structures, RAGs cannot operate, and without Evals, prompt changes cannot be safely deployed.
4. Practice project design
In this series, we continue to advance one project further.
# This is an example.Production-grade LLM Document Q&A ServiceThe goal is to create a backend system that indexes documents similar to official documents, theses, technical blogs, and in-house documents, and provides evidence-based answers to users' questions.
| layer | Initial implementation | direction of advancement |
|---|---|---|
| API | Question creation/inquiry API | Failure response, trace ID, rate limit |
| DB | User, document, and question history | Index status, prompt version, eval result |
| Cache | Redis response cache | token budget, prompt hash, TTL policy |
| Queue | Document Indexing Operations | idempotency, retry, DLQ |
| RAG | pgvector search | reranking, citation, quality eval |
| LLM | External API call | provider routing, timeout, fallback |
| observability | structured log | trace, metrics, dashboard |
| Quality | Manual verification | golden set, regression test |
5. Learning topics for each stage
The first 12 pieces are the MVP of the entire roadmap.
| order | post title | purpose |
|---|---|---|
| 1 | Backend roadmap to take LLM services from PoC to production | Global orientation settings |
| 2 | Why backend basics come before LLM | Learning order persuasion |
| 3 | Designing an operational API | API contracts and traceability |
| 4 | Designing an LLM response cache with Redis Cache Aside | Fundamentals of Cost and Delay Optimization |
| 5 | Queue and Idempotency | Stabilize long operations and retries |
| 6 | Structured Outputs in Practice | Treating Model Outputs as Contracts |
| 7 | function calling Design | LLM and internal API boundaries |
| 8 | prompt caching and token budget | Indicating costs and operational delays |
| 9 | Read the RAG paper from a backend perspective | Practical interpretation of theory |
| 10 | Creating a document-type RAG service with pgvector | Implementation-centric RAG |
| 11 | Introduction to LLM Evals | Quality regression testing |
| 12 | Connecting LLM Request Trace with OpenTelemetry | observability Design |
6. How to read the material
Official documents, papers, and corporate technology blogs should not be read in the same way.
| data | Purpose of Reading | Lab deliverables |
|---|---|---|
| official document | Check API contracts, limits, and settings | Terms of use, notices, code examples |
| thesis | Define the problem and understand the core ideas | Illustration reinterpreted with backend structure |
| Corporate technology blog | Learning practical constraints and trade-offs | Checklist to apply to my project |
7. Practical checklist
# This is an example.[ ] Does this step address a single operational problem?[ ] Have I separated my interpretation from the facts confirmed in official sources?[ ] Are there any implementation or experimental artifacts?[ ] Have you measured one or more of the following: cost, delay, or reliability?[ ] Is there a checklist that other developers can follow?[ ] Is there a learning flow connected to the next article?8. Q&A
Q1. Why not start by studying LangChain or Agent framework?
You can study. However, it is not a suitable topic to grab first. Frameworks speed up implementation, but they don't design failure response, cost tracking, data models, or evaluation criteria for you.
Q2. Do I need to learn how to serve my own model right away?
In the beginning, experience in attaching external APIs reliably is more important. Self-serving is an advanced topic that requires GPUs, batching, autoscaling, and observability together.
Q3. What is the final product of this series?
The final product is not a single document Q&A service, but a design record that has advanced the service into an operable structure. More important than code are decision-making and operating standards.
9. References and uncertainty
References
- OpenAI Structured Outputs Docs:https://platform.openai.com/docs/guides/structured-outputs
- OpenAI function calling Docs:https://platform.openai.com/docs/guides/function-calling
- OpenAI Evals Docs:https://platform.openai.com/docs/guides/evals
- Redis Cache Aside Tutorial:https://redis.io/tutorials/howtos/solutions/microservices/caching/
- AWS Builders Library — Idempotent APIs:https://aws.amazon.com/builders-library/making-retries-safe-with-idempotent-APIs/
- RAG Paper:https://arxiv.org/abs/2005.11401
- pgvector:https://github.com/pgvector/pgvector
- OpenTelemetry Docs:https://opentelemetry.io/docs/
uncertainty
- OpenAI API features and pricing may change depending on model and timing.
- Serving your own model will have significantly different results depending on your GPU environment, model size, and deployment method.
- The practice environment in this article is a reference for learning purposes only, and security, permission, and cost policies must be reflected separately in an actual organizational environment.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.