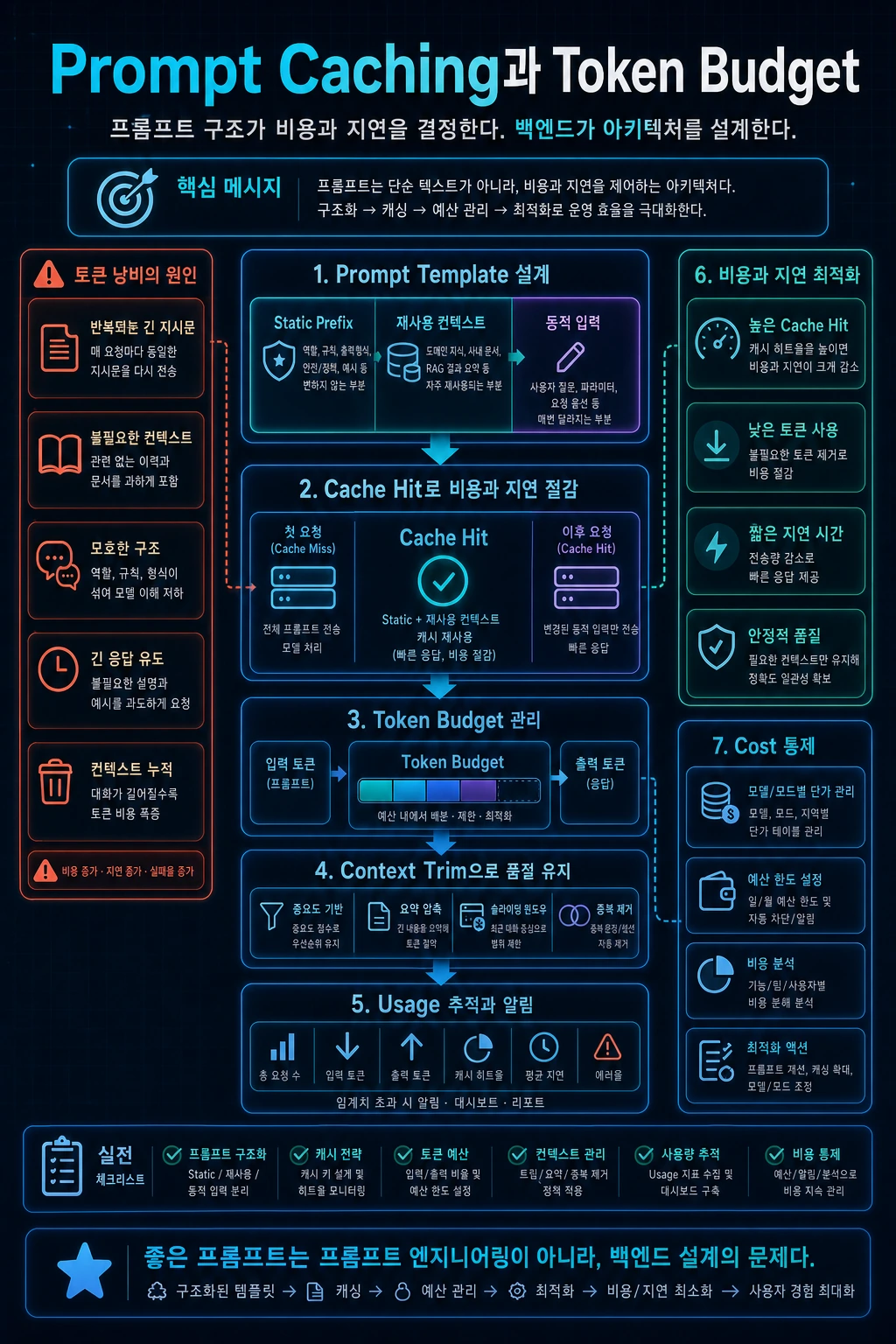
비용과 지연을 줄이는 운영 전략
이 글에서는 Prompt Caching과 Token Budget을 이용해 LLM 서비스의 비용과 지연을 운영 지표로 관리하는 방법을 정리합니다.
LLM 비용은 서버 CPU 비용처럼 고정적으로 나오지 않습니다. 요청마다 input token, output token, 모델, 캐시 여부에 따라 달라집니다. 응답 지연도 마찬가지입니다. 같은 API라도 프롬프트 길이와 검색된 문서 수에 따라 크게 달라집니다.
그래서 LLM 서비스에서는 “프롬프트를 잘 쓰는 법”보다 “프롬프트를 운영 가능한 비용 단위로 관리하는 법”이 중요합니다.
분석 기준일: 2026-05-12
실습 기준 환경: OpenAI API, FastAPI, Redis, Prometheus
주요 참고자료: OpenAI Prompt Caching Docs, OpenAI Rate Limits Docs, OpenAI Cookbook
핵심 요약
- Token Budget은 요청 하나에 허용할 input/output token 한도다.
- Prompt Caching은 반복되는 prompt prefix의 비용과 지연을 줄이는 데 도움이 된다.
- 정적 내용은 prompt 앞쪽에, 동적 내용은 뒤쪽에 두는 방식이 캐시 효율에 유리하다.
- 비용 최적화는 감이 아니라 usage metric으로 해야 한다.
- prompt version별 비용과 품질을 함께 봐야 한다.
1. LLM 비용은 왜 예측하기 어려운가
일반 API는 요청 수와 서버 리소스를 보면 비용을 어느 정도 예측할 수 있습니다. 하지만 LLM은 요청의 길이가 비용을 만듭니다.
| 요소 | 비용 영향 |
|---|---|
| system prompt 길이 | 모든 요청에 반복 비용 발생 |
| 검색된 문서 수 | RAG input token 증가 |
| 대화 이력 | context 길이 증가 |
| 출력 길이 | output token 비용 증가 |
| 재시도 | 같은 비용 반복 발생 |
| 캐시 여부 | input 처리 비용/지연 감소 가능 |
따라서 토큰 사용량을 API 지표로 봐야 합니다.
2. Token Budget이란 무엇인가
Token Budget은 요청 하나에 허용할 토큰 예산입니다.
# 예시입니다.총 budget = system prompt + tool schema + retrieved context + user question + output reserve예시:
| 영역 | 예산 |
|---|---|
| system prompt | 1,000 tokens |
| tool/schema instruction | 800 tokens |
| retrieved context | 4,000 tokens |
| conversation history | 1,000 tokens |
| user question | 300 tokens |
| output reserve | 1,200 tokens |
budget을 넘으면 검색 문서 수를 줄이거나, 오래된 대화 이력을 요약하거나, output max token을 제한해야 합니다.
3. Prompt Caching 기본 개념
Prompt Caching은 반복되는 prompt prefix를 provider가 재사용해 지연과 비용을 줄이는 방식입니다.
실무적으로 중요한 점은 “반복되는 부분이 앞쪽에 있어야 한다”는 것입니다.
# 예시입니다.좋은 구조:[고정 system prompt][고정 tool schema][고정 응답 규칙][동적 검색 문서][동적 사용자 질문] 나쁜 구조:[사용자 질문][검색 문서][고정 system prompt][tool schema]고정 내용이 뒤쪽에 있으면 캐시 prefix 재사용 효과가 떨어질 수 있습니다.
4. 캐시 친화적인 Prompt Layout
추천 layout은 다음과 같습니다.
# 예시입니다.System:- 역할- 답변 정책- citation 규칙- 금지사항- schema 설명 Developer:- tool 사용 규칙- output validation 기준 Context:- retrieved chunks User:- question변하지 않는 정책은 앞에 두고, 요청마다 달라지는 문서와 질문은 뒤에 둡니다.
5. RAG에서 token budget 나누기
RAG는 token budget 관리가 특히 중요합니다. 검색 결과를 많이 넣는다고 항상 답변이 좋아지지 않습니다. 오히려 관련 없는 chunk가 늘면 모델이 혼란스러워질 수 있습니다.
| 전략 | 설명 |
|---|---|
| Top-k 제한 | 검색 결과 개수 제한 |
| Chunk 압축 | 긴 chunk를 요약 후 입력 |
| Metadata filter | 권한, 문서 유형, 날짜로 후보 줄이기 |
| Reranking | 관련도 높은 문서만 남기기 |
| Output reserve | 답변에 필요한 token 공간 확보 |
6. 비용·지연 지표 설계
반드시 남길 metric:
# 예시입니다.llm_input_tokens_totalllm_output_tokens_totalllm_cached_input_tokens_totalllm_cost_estimated_totalllm_latency_ms_bucketllm_prompt_version_usage_totalllm_rate_limit_error_totalllm_retry_total분석 기준:
| 질문 | 볼 지표 |
|---|---|
| 어떤 prompt version이 비싼가? | version별 token usage |
| 캐시가 효과 있는가? | cached token ratio |
| 지연이 어디서 생기는가? | latency p95/p99 |
| 재시도 비용이 큰가? | retry count, retry token |
7. Rate Limit과 Backoff
Rate limit은 단순히 더 높은 요금제를 쓰면 해결되는 문제가 아닙니다. burst traffic, retry storm, 대량 eval 실행이 함께 오면 제한에 걸릴 수 있습니다.
대응 원칙:
# 예시입니다.[ ] 요청 단위 rate limit[ ] 사용자/조직 단위 quota[ ] eval batch 별도 제한[ ] exponential backoff[ ] retry budget[ ] provider fallback8. 실무 예제
프롬프트 호출 전 budget check:
# 예시 코드입니다.def enforce_token_budget(parts: dict, max_input_tokens: int): estimated = sum(estimate_tokens(value) for value in parts.values()) if estimated <= max_input_tokens: return parts parts["retrieved_context"] = trim_context(parts["retrieved_context"]) estimated = sum(estimate_tokens(value) for value in parts.values()) if estimated > max_input_tokens: raise ValueError("TOKEN_BUDGET_EXCEEDED") return parts실제 서비스에서는 tokenizer 기반 추정과 provider usage 결과를 함께 기록해야 합니다.
9. 실무 체크리스트
# 예시입니다.[ ] 요청당 input/output token budget을 정했는가?[ ] prompt version별 token usage를 기록하는가?[ ] 정적 prompt prefix를 앞쪽에 배치했는가?[ ] RAG context top-k와 최대 token을 제한했는가?[ ] output reserve를 확보했는가?[ ] cached input token 비율을 측정하는가?[ ] rate limit 오류와 retry 비용을 기록하는가?[ ] eval 실행과 사용자 트래픽의 quota를 분리했는가?실패 사례: 캐시는 켰지만 비용이 줄지 않은 경우
Prompt Caching을 적용했는데 비용과 지연이 거의 줄지 않는 경우가 있습니다. 대개 반복되는 prefix가 짧거나, 매 요청마다 system prompt 앞부분이 달라지거나, 검색 문서가 prompt의 앞쪽에 끼어들기 때문입니다. provider가 cache를 지원해도 prompt layout이 캐시에 맞지 않으면 효과가 작습니다.
또 하나의 실패는 평균 token만 보는 것입니다. LLM 비용은 p95와 p99 요청이 크게 흔듭니다. 대부분 요청은 짧지만 일부 요청이 긴 문서 20개를 넣고, 긴 답변까지 생성하면 월 비용 추정이 틀어집니다. token budget은 평균 최적화가 아니라 요청별 상한과 예외 처리를 정하는 운영 정책입니다.
구현 예시: prompt layout을 cache-friendly하게 나누기
[stable prefix]- product role- response policy- tool contract- safety and citation rules [semi-stable]- tenant policy version- prompt template version [dynamic suffix]- user question- retrieved chunks- conversation summary정적인 정책은 앞쪽에 두고, 질문과 검색 결과는 뒤쪽에 둡니다. template version이 바뀌면 cache hit가 줄어드는 것을 정상 이벤트로 보고 metric에 남깁니다. dynamic suffix가 budget을 넘으면 retrieval top-k를 줄이거나 요약 context로 대체해야 합니다.
체크리스트 적용 결과
| 지표 | 수집 이유 | 대응 예 |
|---|---|---|
| input tokens | 요청 비용의 기본 단위 | retrieval chunk 수 제한 |
| cached input tokens | caching 효과 확인 | stable prefix 재배치 |
| output tokens | 답변 길이와 비용 관리 | answer policy와 max token 조정 |
| prompt version | 변경 전후 비교 | regression eval 연결 |
| p95 latency | 긴 요청 감지 | timeout과 fallback 설계 |
이 지표가 있으면 "프롬프트가 길어서 비싸다"가 아니라 "version 7에서 cached input 비율이 떨어졌고 retrieval suffix가 p95를 밀어 올렸다"처럼 원인을 말할 수 있습니다. 비용 최적화는 문장 감각보다 측정 가능한 budget 관리에 가깝습니다.
실패 대응 예시: 긴 문서 질문의 budget 초과
사용자가 80쪽짜리 정책 문서를 업로드하고 "전체 내용을 요약하고 예외 조항을 찾아줘"라고 요청했다고 해봅시다. 좋은 backend는 바로 전체 문서를 prompt에 넣지 않습니다. 먼저 문서 길이, chunk 수, 질문 유형을 보고 budget plan을 만듭니다.
| 선택지 | 장점 | 위험 |
|---|---|---|
| 전체 문서 입력 | 구현이 단순 | 비용 폭주, context 초과 |
| top-k chunk만 입력 | 비용 제어 | 중요한 조항 누락 가능 |
| map-reduce 요약 | 긴 문서 처리 가능 | 단계별 지연 증가 |
| 질문 재작성 후 retrieval | 관련도 개선 | rewrite 품질 의존 |
운영에서는 질문 유형별 budget을 다르게 둡니다. 단순 정의 질문은 top-k를 작게 잡고 output reserve도 적게 둡니다. 비교 분석이나 예외 조항 탐색은 retrieval 후보를 넓히되, 중간 요약을 만들고 최종 답변에는 source chunk만 넣습니다. 이때 prompt caching은 고정 policy와 schema에는 도움이 되지만 업로드 문서 자체에는 큰 효과가 없을 수 있습니다.
경계 사례는 retry storm입니다. rate limit 오류가 났을 때 같은 긴 prompt를 여러 번 재시도하면 비용과 지연이 동시에 커집니다. retry budget을 별도로 두고, budget을 넘으면 "문서를 나눠 처리하겠다"거나 "더 좁은 질문이 필요하다"고 사용자에게 안내해야 합니다. token budget은 단순 최적화가 아니라 실패를 제품 경험으로 바꾸는 장치입니다.
10. Q&A
Q1. Prompt Caching만으로 비용 문제가 해결되나요?
아닙니다. Prompt Caching은 반복 prefix에 유리합니다. RAG context나 사용자 질문처럼 매번 달라지는 부분은 token budget과 retrieval 품질 개선이 필요합니다.
Q2. system prompt를 길게 써도 괜찮나요?
반복되고 캐시가 잘 적용된다면 비용 부담이 줄 수 있습니다. 하지만 긴 system prompt는 유지보수와 품질 회귀 리스크를 만들기 때문에 versioning과 eval이 필요합니다.
Q3. output token도 캐시되나요?
Prompt Caching은 주로 입력 prefix 재사용과 관련됩니다. 출력 길이는 별도 max token과 답변 정책으로 관리해야 합니다.
11. 참고자료와 불확실성
참고자료
- OpenAI Prompt Caching: https://platform.openai.com/docs/guides/prompt-caching
- OpenAI Rate Limits: https://platform.openai.com/docs/guides/rate-limits
- OpenAI Cookbook — Prompt Caching: https://developers.openai.com/cookbook/examples/prompt_caching_201
불확실성
- 캐시 적용 조건, 지원 모델, 가격 정책은 시점에 따라 달라질 수 있습니다.
- token 추정은 실제 provider usage와 차이가 날 수 있습니다.
Operational strategies to reduce costs and delays
In this article, we summarize how to manage the cost and delay of LLM services as operational indicators using prompt caching and token budget.
LLM costs are not fixed like server CPU costs. Each request depends on the input token, output token, model, and whether or not it is cached. The same goes for response delays. Even within the same API, the length of the prompt and the number of documents retrieved can vary greatly.
Therefore, in LLM services, “how to manage prompts as an operable cost unit” is more important than “how to write prompts well.”
Analysis date: 2026-05-12 Practice environment: OpenAI API, FastAPI, Redis, Prometheus Main reference materials: OpenAI prompt caching Docs, OpenAI Rate Limits Docs, OpenAI Cookbook
Key takeaways
- token budget is the input/output token limit allowed for one request.
- prompt caching helps reduce the cost and delay of repeated prompt prefixes.
- Placing static content at the front of the prompt and dynamic content at the back is advantageous for cache efficiency.
- Cost optimization should be based on usage metrics, not intuition.
- Cost and quality for each prompt version must be looked at together.
1. Why LLM costs are difficult to predict
For regular APIs, the cost can be somewhat estimated by looking at the number of requests and server resources. But with LLM, the length of the request creates a cost.
| element | cost impact |
|---|---|
| system prompt length | Recurring costs for every request |
| Number of documents retrieved | Increase RAG input token |
| conversation history | Increase context length |
| output length | Increased output token cost |
| retry | Same costs occur repeatedly |
| Cache or not? | Input processing cost/delay can be reduced |
Therefore, token usage should be viewed as an API metric.
2. What is token budget?
token budget is the token budget to allow for one request.
# This is an example.Total budget = system prompt + tool schema + retrieved context + user question + output reserveexample:
| area | budget |
|---|---|
| system prompt | 1,000 tokens |
| tool/schema instruction | 800 tokens |
| retrieved context | 4,000 tokens |
| conversation history | 1,000 tokens |
| user question | 300 tokens |
| output reserve | 1,200 tokens |
If you exceed your budget, you may need to reduce the number of search documents, summarize old conversation history, or limit output max tokens.
3. prompt caching basic concept
prompt caching is a method in which the provider reuses repeated prompt prefixes to reduce delays and costs.
What is important in practice is that “repeated parts should be at the front.”
# This is an example.Good structure:[fixed system prompt][Fixed tool schema][Fixed response rules][Dynamic Search Document][Dynamic User Questions] Bad structure:[User Question][Search Document][fixed system prompt][tool schema]Cache prefix reuse may be less effective if the fix content is located later.
4. Cache-friendly Prompt Layout
The recommended layout is as follows.
# This is an example.System:- Role- Reply Policy- citation rules- Prohibitions- Schema description Developer:- Tool use rules- Output validation criteria Context:- retrieved chunks User:- questionPolicies that do not change are placed first, and documents and questions that change with each request are placed last.
5. Divide token budget in RAG
For RAG, token budget management is especially important. Entering more search results does not always result in better answers. Rather, if the number of unrelated chunks increases, the model may become confused.
| strategy | explanation |
|---|---|
| Top-k limits | Limit the number of search results |
| Chunk compression | Summarize long chunks and then enter them |
| metadata filter | Reduce candidates by permissions, document type, and date |
| reranking | Leave only highly relevant documents |
| Output reserve | Secure token space required for response |
6. Cost/delay indicator design
Be sure to leave metrics:
# This is an example.llm_input_tokens_totalllm_output_tokens_totalllm_cached_input_tokens_totalllm_cost_estimated_totalllm_latency_ms_bucketllm_prompt_version_usage_totalllm_rate_limit_error_totalllm_retry_totalAnalysis criteria:
| question | ball indicators |
|---|---|
| Which prompt version is more expensive? | Token usage by version |
| Is Cache Effective? | cached token ratio |
| Where does the delay come from? | latency p95/p99 |
| Are retries expensive? | retry count, retry token |
7. Rate Limit and Backoff
Rate limits are not a problem that can be solved by simply using a higher rate plan. Combining burst traffic, retry storms, and bulk eval executions can lead to throttling.
Response principles:
# This is an example.[ ] Request unit rate limit[ ] User/Organizational Unit Quota[ ] eval batch separate restrictions[ ] exponential backoff[ ] retry budget[ ] provider fallback8. Practical example
Budget check before calling prompt:
# This is example code.def enforce_token_budget(parts: dict, max_input_tokens: int): estimated = sum(estimate_tokens(value) for value in parts.values()) if estimated <= max_input_tokens: return parts parts["retrieved_context"] = trim_context(parts["retrieved_context"]) estimated = sum(estimate_tokens(value) for value in parts.values()) if estimated > max_input_tokens: raise ValueError("TOKEN_BUDGET_EXCEEDED") return partsIn actual services, tokenizer-based estimation and provider usage results must be recorded together.
9. Practical checklist
# This is an example.[ ] Have you set an input/output token budget per request?[ ] Do you record token usage by prompt version?[ ] Did you place the static prompt prefix in front?[ ] Are the RAG context top-k and maximum tokens limited?[ ] Have you secured the output reserve?[ ] Do you measure the cached input token ratio?[ ] Are rate limit errors and retry costs recorded?[ ] Have you separated quotas for eval execution and user traffic?Failure case: Cache is turned on but costs are not reduced
There are cases where prompt caching is applied but costs and delays are hardly reduced. This is usually because the repeated prefix is short, the beginning of the system prompt changes for each request, or the search document is inserted into the beginning of the prompt. Even if the provider supports cache, the effect will be small if the prompt layout does not fit the cache.
Another failure is to only look at the average token. LLM fees vary greatly with p95 and p99 requests. Most requests are short, but if some requests include 20 long documents and generate long responses, the monthly cost estimate will be wrong. The token budget is not an average optimization, but rather an operational policy that sets per-request upper limits and exception handling.
Implementation example: Dividing the prompt layout into cache-friendly
[stable prefix]- product role- response policy- tool contract- safety and citation rules [semi-stable]- tenant policy version- prompt template version [dynamic suffix]- user question- retrieved chunks- conversation summaryPut static policies at the front, and questions and search results at the back. When the template version changes, the decrease in cache hits is considered a normal event and recorded in the metrics. If the dynamic suffix exceeds the budget, the retrieval top-k should be reduced or replaced with a summary context.
Checklist application results
| characteristic | Reason for collection | Correspondence example |
|---|---|---|
| input tokens | Base unit of request cost | Limit number of retrieval chunks |
| cached input tokens | Check caching effect | stable prefix relocation |
| output tokens | Manage answer length and cost | Adjust answer policy and max token |
| prompt version | Comparison before and after changes | regression eval connection |
| p95 latency | Long request detection | Timeout and fallback design |
Having this metric allows you to say the cause, not like "the prompts are long and that's expensive", but something like "the cached input rate dropped in version 7 and the retrieval suffix pushed up p95". Cost optimization is more about measurable budget management than it is about statement sense.
Example of failure response: Budget exceeded for long document question
Let's say a user uploads an 80-page policy document and asks, "Summary everything and find exceptions." A good backend doesn't immediately put the entire document into the prompt. First, create a budget plan by looking at the document length, number of chunks, and question types.
| Choice | merit | danger |
|---|---|---|
| Enter the entire document | Simple implementation | Cost surge, context exceeded |
| Enter only top-k chunk | cost control | Possible omission of important provisions |
| map-reduce summary | Capable of processing long documents | Step by step increase in delay |
| retrieval after rewriting the question | Improved relevance | rewrite quality depend |
In operations, budgets are set differently for each question type. For simple definition questions, keep top-k small and output reserve small. Comparative analysis or exception clause exploration broadens the retrieval candidates, but creates intermediate summaries and includes only source chunks in the final answer. In this case, prompt caching is helpful for fixed policies and schemas, but may not have much effect on the upload document itself.
A borderline case is a retry storm. When a rate limit error occurs, retrying the same long prompt multiple times increases both cost and delay. You should set a separate retry budget, and if it exceeds the budget, you should inform the user that “the documents will be processed separately” or “a narrower question is needed.” token budget is not a simple optimization, but a device that turns failure into a product experience.
10. Q&A
Q1. Does prompt caching alone solve the cost problem?
no. prompt caching is advantageous for repetitive prefixes. Areas that change every time, such as RAG context or user questions, require improvement in token budget and retrieval quality.
Q2. Is it okay to use the system prompt for a long time?
If it is repeated and cached well, the cost burden can be reduced. However, long system prompts create maintenance and quality regression risks, so versioning and eval are necessary.
Q3. Are output tokens also cached?
prompt caching is primarily concerned with input prefix reuse. The output length must be managed separately with max token and response policy.
11. References and uncertainty
References
- OpenAI prompt caching:https://platform.openai.com/docs/guides/prompt-caching
- OpenAI Rate Limits:https://platform.openai.com/docs/guides/rate-limits
- OpenAI Cookbook — prompt caching:https://developers.openai.com/cookbook/examples/prompt_caching_201
uncertainty
- Cache application terms, support models, and pricing may vary from time to time.
- Token estimation may differ from actual provider usage.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.