모델 출력을 JSON Schema 계약으로 만들기
이 글에서는 Structured Outputs를 이용해 LLM 응답을 JSON Schema 기반 계약으로 다루는 방법을 정리합니다.
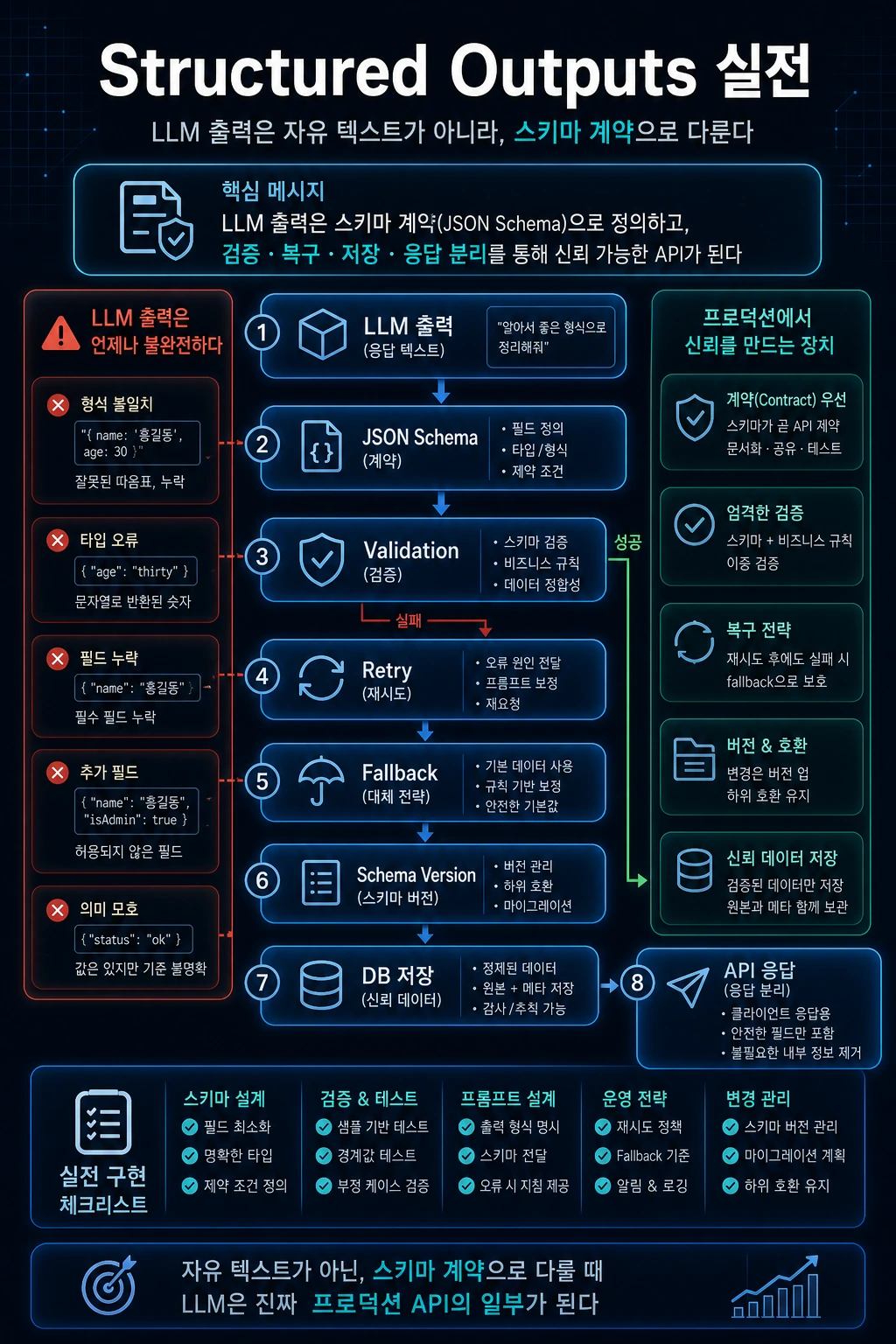
LLM 응답을 서비스에 붙일 때 가장 먼저 부딪히는 문제는 “답변이 그럴듯한가”가 아닙니다. “백엔드가 파싱할 수 있는가”입니다.
모델이 자유 텍스트로 답변하면 프론트엔드, DB, 후속 API가 안정적으로 사용할 수 없습니다. 특히 문서 요약, 정보 추출, 분류, 라우팅, 툴 호출 전처리처럼 구조화된 결과가 필요한 작업에서는 모델 출력을 계약으로 만들어야 합니다.
분석 기준일: 2026-05-12
실습 기준 환경: OpenAI API, Python, Pydantic, FastAPI
주요 참고자료: OpenAI Structured Outputs Docs, JSON Schema, Pydantic
핵심 요약
- Structured Outputs는 모델 응답이 지정한 JSON Schema를 따르도록 만드는 기능이다.
- LLM 응답은 서비스 내부에서 API response와 같은 계약으로 다뤄야 한다.
- schema version을 두지 않으면 프롬프트 변경과 응답 구조 변경을 추적하기 어렵다.
- validation 실패는 정상 운영 시나리오로 보고 retry/fallback을 설계해야 한다.
- 모든 필드를 모델에게 맡기지 말고 서버가 계산할 필드는 서버에서 채워야 한다.
1. 왜 구조화된 출력이 필요한가
자유 텍스트 응답은 사람이 읽기에는 좋지만 시스템이 처리하기에는 어렵습니다.
예를 들어 모델에게 아래처럼 요청했다고 가정해보겠습니다.
# 예시입니다.이 문서의 핵심 내용을 요약하고, 출처와 신뢰도를 포함해줘.모델은 다양한 형태로 답할 수 있습니다.
# 예시입니다.핵심은 Redis 캐시가 DB 부하를 줄인다는 점입니다. 출처는 Redis 공식문서입니다.또는:
# 예시입니다.{ "summary": "Redis 캐시는 DB 부하를 줄인다", "source": "Redis Docs"}서비스는 이런 변동성을 싫어합니다. 프론트엔드는 citations 배열을 기대하는데 모델이 source 문자열을 주면 깨집니다.
2. JSON mode와 Structured Outputs의 차이
JSON mode는 유효한 JSON을 생성하는 데 도움을 줍니다. 하지만 특정 schema를 반드시 지키는 것과는 다릅니다.
Structured Outputs는 응답이 개발자가 정의한 JSON Schema를 따르도록 하는 데 초점을 둡니다.
| 구분 | JSON mode | Structured Outputs |
|---|---|---|
| 목표 | JSON 형식 출력 | JSON Schema 준수 |
| 필수 필드 보장 | 약함 | 강함 |
| enum 제약 | 약함 | schema 기반 |
| API 계약 적합성 | 제한적 | 높음 |
실무적으로는 JSON mode보다 schema 기반 출력이 더 안전합니다.
3. 응답 schema 설계 원칙
좋은 schema는 모델에게 모든 것을 맡기지 않습니다.
| 원칙 | 설명 |
|---|---|
| 필요한 필드만 둔다 | 과한 필드는 실패율을 높인다 |
| enum을 적극 사용한다 | 후속 분기 안정성 확보 |
| 서버 계산 필드는 제외한다 | token usage, trace_id 등은 서버가 채운다 |
| nullable을 신중히 쓴다 | null 허용은 후속 처리 복잡도 증가 |
| version을 둔다 | schema 변경 추적 |
4. 문서 Q&A 응답 schema 예제
// 예시 JSON 구조입니다.{ "type": "object", "properties": { "answer": { "type": "string", "description": "사용자 질문에 대한 답변" }, "confidence": { "type": "string", "enum": ["high", "medium", "low"] }, "citations": { "type": "array", "items": { "type": "object", "properties": { "document_id": { "type": "string" }, "chunk_id": { "type": "string" }, "quote": { "type": "string" } }, "required": ["document_id", "chunk_id", "quote"] } }, "needs_human_review": { "type": "boolean" } }, "required": ["answer", "confidence", "citations", "needs_human_review"], "additionalProperties": false}이 schema는 답변, 신뢰도, 출처, 검토 필요 여부를 명확히 분리합니다.
5. Validation과 fallback
Structured Outputs를 사용해도 백엔드 validation은 필요합니다. 외부 시스템의 출력은 항상 검증해야 합니다.
# 예시 코드입니다.from pydantic import BaseModelfrom typing import Literal # 이 선언은 예시 흐름을 보여줍니다.class Citation(BaseModel): document_id: str chunk_id: str quote: str # 이 선언은 예시 흐름을 보여줍니다.class AnswerOutput(BaseModel): answer: str confidence: Literal["high", "medium", "low"] citations: list[Citation] needs_human_review: bool실패 시나리오:
# 예시입니다.1. 모델 응답 schema validation 실패2. 한 번 재시도3. 그래도 실패하면 fallback 응답 반환4. eval/debug dataset에 실패 케이스 저장Fallback 예시:
// 예시 JSON 구조입니다.{ "answer": "답변을 안정적으로 생성하지 못했습니다. 질문을 조금 더 구체적으로 입력해 주세요.", "confidence": "low", "citations": [], "needs_human_review": true}6. Schema versioning
응답 구조는 시간이 지나며 바뀝니다. 따라서 schema version이 필요합니다.
# 예시입니다.answer.v1answer.v2classification.v1extraction.receipt.v1schema version은 prompt version과 함께 기록해야 합니다.
| 기록 항목 | 이유 |
|---|---|
schema_version | 응답 구조 추적 |
prompt_version | 프롬프트 변경 추적 |
model | 모델별 품질 비교 |
validation_result | 실패율 분석 |
7. DB 저장과 API 응답 분리
모델 출력 schema와 API 응답 schema를 완전히 같게 만들 필요는 없습니다.
모델 출력:
// 예시 JSON 구조입니다.{ "answer": "...", "confidence": "high", "citations": []}API 응답:
// 예시 JSON 구조입니다.{ "answer_id": "ans_123", "answer": "...", "confidence": "high", "citations": [], "usage": { "input_tokens": 1000, "output_tokens": 300 }, "trace_id": "0af..."}usage, trace_id, answer_id는 서버가 붙이는 값입니다.
8. 실무 리스크
| 리스크 | 대응 |
|---|---|
| schema가 너무 복잡함 | 작은 schema부터 시작 |
| enum이 현실을 못 담음 | unknown 또는 needs_review 설계 |
| 모델이 출처를 꾸며냄 | citation은 검색 결과 chunk_id에서만 선택하도록 제한 |
| schema 변경 시 클라이언트 깨짐 | versioning과 migration |
| validation 실패를 장애로만 봄 | 정상 운영 지표로 수집 |
9. 실무 체크리스트
# 예시입니다.[ ] 모델 출력 schema와 API 응답 schema를 구분했는가?[ ] required 필드가 명확한가?[ ] additionalProperties를 제한했는가?[ ] enum 값이 후속 로직과 연결되는가?[ ] schema_version을 저장하는가?[ ] validation 실패율을 metric으로 남기는가?[ ] 실패 시 retry/fallback 정책이 있는가?[ ] citation을 모델이 임의 생성하지 못하게 했는가?실패 사례: JSON은 받았지만 계약은 없었던 경우
Structured Outputs를 쓴다고 해서 곧바로 안정적인 API 계약이 생기지는 않습니다. 가장 흔한 실패는 schema를 만들었지만 version, validation, fallback 정책이 없는 경우입니다. 모델은 JSON을 반환하고 parser도 통과하지만, downstream service가 기대한 의미와 다를 수 있습니다. 예를 들어 risk: "medium"이 어떤 threshold를 뜻하는지 문서화되지 않으면 UI, DB, alert rule이 서로 다르게 해석합니다.
또 다른 문제는 모든 필드를 모델에게 맡기는 것입니다. createdAt, sourceId, confidenceScore, needsReview 같은 값은 일부는 서버가 계산해야 합니다. 모델이 채운 timestamp나 내부 id를 그대로 믿으면 데이터 정합성이 깨집니다. Structured Outputs는 출력 형식을 제어하는 도구이지, business rule 검증을 대체하는 도구가 아닙니다.
구현 예시: schema version과 서버 계산 필드
type ExtractionV1 = { schemaVersion: "customer_intent.v1"; intent: "refund" | "upgrade" | "bug_report" | "unknown"; evidence: string[]; modelConfidence: number;}; type StoredExtraction = ExtractionV1 & { requestId: string; validatedAt: string; needsReview: boolean;};모델은 ExtractionV1만 생성합니다. 서버는 requestId, validatedAt, needsReview를 계산합니다. 특히 needsReview는 모델 confidence만 보지 않고 사용자 등급, 민감 키워드, 이전 실패 이력 같은 서버 정보를 함께 봐야 합니다.
비교표: 출력 형식과 운영 계약
| 항목 | Structured Outputs가 도와주는 것 | 서버가 계속 해야 하는 것 |
|---|---|---|
| JSON 형식 | schema에 맞는 응답 생성 | 파싱 실패와 재시도 처리 |
| enum | 허용 값 제한 | 값의 business 의미 정의 |
| required field | 필드 누락 감소 | 신뢰할 수 없는 값 재계산 |
| schema | 구조 고정 | version migration과 호환성 |
이 표를 기준으로 보면 Structured Outputs는 validation layer의 앞단입니다. 백엔드는 여전히 외부 입력을 검증해야 하고, 저장 전에는 business invariant를 확인해야 합니다. 그래야 모델 교체나 prompt 변경이 downstream 장애로 바로 이어지지 않습니다.
실무 적용 예시: 문의 분류 결과 저장
고객 문의를 refund, billing, bug, account 같은 intent로 분류하는 기능을 만든다고 해봅시다. 모델 출력 schema는 작게 유지하는 편이 좋습니다.
{ "schemaVersion": "ticket_intent.v1", "intent": "billing", "evidence": ["invoice number", "charged twice"], "confidence": "medium"}여기서 서버는 requestId, receivedAt, customerId, needsHumanReview를 별도로 붙입니다. 특히 needsHumanReview는 모델 confidence 하나로 결정하지 않습니다. 환불, 개인정보, 결제 실패처럼 민감한 intent는 confidence가 높아도 검토 대상으로 보낼 수 있습니다.
실패 사례는 schema를 너무 빨리 크게 만드는 것입니다. 처음부터 department, assignee, refundAmount, legalRisk, replyDraft까지 한 번에 받으면 모델은 형식은 맞춰도 business 의미를 섞기 쉽습니다. 분류 schema와 답변 초안 schema를 분리하면 실패 범위가 줄어듭니다. 분류가 틀려도 답변 생성은 시작하지 않을 수 있고, 답변 초안이 실패해도 분류 로그는 남길 수 있습니다.
비교 기준은 단순합니다. Structured Outputs가 보장하는 것은 "응답이 schema 모양에 가깝다"는 점입니다. 서비스가 보장해야 하는 것은 "그 값이 현재 사용자, 권한, DB 상태, 정책에 맞다"는 점입니다. 이 둘을 분리해야 JSON을 받았다는 이유만으로 잘못된 후속 API가 실행되는 사고를 막을 수 있습니다.
10. Q&A
Q1. Structured Outputs를 쓰면 validation 코드를 안 써도 되나요?
아닙니다. 백엔드에서는 여전히 validation을 해야 합니다. 외부 시스템 결과를 신뢰하지 않는 것이 기본입니다.
Q2. 모든 LLM 응답을 JSON으로 만들어야 하나요?
아닙니다. 사용자에게 보여줄 최종 답변은 Markdown일 수 있습니다. 다만 시스템이 후속 처리해야 하는 값은 구조화하는 것이 좋습니다.
Q3. schema가 너무 커지면 어떻게 하나요?
작게 나누는 편이 좋습니다. 추출, 분류, 답변, 검토 필요 여부를 하나의 거대한 schema에 넣기보다 단계별 schema로 분리합니다.
11. 참고자료와 불확실성
참고자료
- OpenAI Structured Outputs: https://platform.openai.com/docs/guides/structured-outputs
- JSON Schema: https://json-schema.org/
- Pydantic: https://docs.pydantic.dev/
불확실성
- 지원 모델과 API 세부 파라미터는 시점에 따라 바뀔 수 있습니다.
- 복잡한 schema의 성능과 실패율은 실제 테스트가 필요합니다.
Create model output as a JSON Schema contract
In this article, we summarize how to use Structured Outputs to handle LLM responses as JSON Schema-based contracts.
The first question you encounter when attaching an LLM response to a service is not “Is the answer plausible?” “Can the backend parse it?”
If your model answers in free text, your frontend, DB, and subsequent APIs won't be able to use it reliably. In particular, tasks that require structured results, such as document summarization, information extraction, classification, routing, and tool call preprocessing, require model outputs to be contracts.
Analysis base date: 2026-05-12 Practice standard environment: OpenAI API, Python, Pydantic, FastAPI Main reference materials: OpenAI Structured Outputs Docs, JSON Schema, Pydantic
Key takeaways
- Structured Outputs is a function that makes model responses follow the specified JSON Schema.
- LLM responses must be treated as contracts like API responses within the service.
- Without a schema version, it is difficult to track changes in prompts and response structures.
- Validation failure should be viewed as a normal operating scenario and a retry/fallback should be designed.
- Instead of leaving all fields to the model, the fields to be calculated by the server should be filled in by the server.
1. Why Structured Outputs?
Free text responses are great for humans to read, but difficult for systems to process.
For example, let's say you made the following request to the model:
# This is an example.Summarize the main content of this document and include sources and credibility.The model can answer in many different ways.
# This is an example.The key point is that Redis cache reduces DB load. The source is the Redis official document.or:
# This is an example.{"summary": "Redis cache reduces DB load","source": "Redis Docs"}Services hate this volatility. The frontend expects an array ofcitations, but if the model gives it the stringsource, it breaks.
2. Difference between JSON mode and Structured Outputs
JSON mode helps you generate valid JSON. However, this is different from necessarily adhering to a specific schema.
Structured Outputs focuses on ensuring that the response follows the JSON Schema defined by the developer.
| division | JSON mode | Structured Outputs |
|---|---|---|
| target | JSON format output | JSON Schema compliance |
| Ensure required fields | weakness | strong |
| enum constraints | weakness | schema based |
| API contract compliance | limited | height |
In practice, schema-based output is safer than JSON mode.
3. Response schema design principles
A good schema doesn't leave everything to the model.
| principle | explanation |
|---|---|
| Leave only the fields you need | Excessive fields increase the failure rate |
| Actively use enums | Ensure stability in subsequent quarters |
| Exclude server calculated fields | Token usage, trace_id, etc. are filled in by the server. |
| Use nullable carefully | Nullability increases subsequent processing complexity |
| put version | Schema change tracking |
4. Document Q&A response schema example
// This is an example JSON structure.{ "type": "object", "properties": { "answer": { "type": "string", "description": "Answers to user questions" }, "confidence": { "type": "string", "enum": ["high", "medium", "low"] }, "citations": { "type": "array", "items": { "type": "object", "properties": { "document_id": { "type": "string" }, "chunk_id": { "type": "string" }, "quote": { "type": "string" } }, "required": ["document_id", "chunk_id", "quote"] } }, "needs_human_review": { "type": "boolean" } }, "required": ["answer", "confidence", "citations", "needs_human_review"], "additionalProperties": false}This schema clearly separates answers, their credibility, source, and whether they require review.
5. Validation and fallback
Even when using Structured Outputs, backend validation is required. Output from external systems should always be verified.
# This is example code.from pydantic import BaseModelfrom typing import Literal # This declaration shows an example flow.class Citation(BaseModel): document_id: str chunk_id: str quote: str # This declaration shows an example flow.class AnswerOutput(BaseModel): answer: str confidence: Literal["high", "medium", "low"] citations: list[Citation] needs_human_review: boolFailure Scenario:
# This is an example.1. Model response schema validation failed2. Retry once3. If it still fails, return a fallback response4. Save failure cases in eval/debug datasetFallback example:
// This is an example JSON structure.{ "answer": "Could not reliably generate answers. Please be a little more specific with your question.", "confidence": "low", "citations": [], "needs_human_review": true}6. Schema versioning
Response structures change over time. Therefore, schema version is required.
# This is an example.answer.v1answer.v2classification.v1extraction.receipt.v1The schema version must be recorded along with the prompt version.
| record entry | reason |
|---|---|
schema_version | Response structure tracking |
prompt_version | Track prompt changes |
model | Quality comparison by model |
validation_result | Failure rate analysis |
7. Separate DB storage and API response
There is no need to make the model output schema and API response schema exactly the same.
Model output:
// This is an example JSON structure.{ "answer": "...", "confidence": "high", "citations": []}API response:
// This is an example JSON structure.{ "answer_id": "ans_123", "answer": "...", "confidence": "high", "citations": [], "usage": { "input_tokens": 1000, "output_tokens": 300 }, "trace_id": "0af..."}usage,trace_id, andanswer_idare values added by the server.
8. Practice risks
| risk | react |
|---|---|
| Schema is too complex | Start with a small schema |
| enum does not contain reality | unknown or needs_review design |
| Model fabricates origin | Citations are limited to selection only by search result chunk_id |
| Client crashes when changing schema | versioning and migration |
| View validation failure only as a failure | Collected as normal operating indicators |
9. Practical checklist
# This is an example.[ ] Did you distinguish between model output schema and API response schema?[ ] Are the required fields clear?[ ] Have you restricted additionalProperties?[ ] Are enum values connected to subsequent logic?[ ] Do you save schema_version?[ ] Is the validation failure rate recorded as a metric?[ ] Is there a retry/fallback policy in case of failure?[ ] Did you prevent the model from randomly generating citations?Failure case: JSON received but no contract
Using Structured Outputs does not immediately create a stable API contract. The most common failure is when you create a schema but don't have a version, validation, or fallback policy. The model returns JSON, which the parser also passes, but the meaning may not be what the downstream service expects. For example, if it is not documented what thresholdrisk: "medium"means, the UI, DB, and alert rule interpret it differently.
Another problem is leaving all the fields to the model. Some values, such ascreatedAt,sourceId,confidenceScore, andneedsReview, must be calculated by the server. If you trust the timestamp or internal ID filled in by the model, data consistency will be broken. Structured Outputs is a tool for controlling output format, not a replacement for business rule validation.
Example implementation: schema version and server calculated fields
type ExtractionV1 = { schemaVersion: "customer_intent.v1"; intent: "refund" | "upgrade" | "bug_report" | "unknown"; evidence: string[]; modelConfidence: number;}; type StoredExtraction = ExtractionV1 & { requestId: string; validatedAt: string; needsReview: boolean;};The model only producesExtractionV1. The server calculatesrequestId,validatedAt,needsReview. In particular,needsReviewmust not only look at model confidence, but also look at server information such as user rating, sensitive keywords, and previous failure history.
Comparison table: output formats and operating agreements
| item | What Structured Outputs can help you with | What the server must continue to do |
|---|---|---|
| JSON format | Generate response matching schema | Handling parsing failures and retries |
| enum | Allowed value limits | Define the business meaning of the value |
| required field | Reduce missing fields | Recalculate Untrusted Values |
| schema | structural fixation | Compatibility with version migration |
Based on this table, Structured Outputs are at the front of the validation layer. The backend still needs to validate external input and check for business invariants before saving. This ensures that model replacement or prompt changes do not directly lead to downstream failures.
Practical application example: storing inquiry classification results
Let's say you want to create a function that classifies customer inquiries into intents such as refund, billing, bug, and account. It is best to keep the model output schema small.
{ "schemaVersion": "ticket_intent.v1", "intent": "billing", "evidence": ["invoice number", "charged twice"], "confidence": "medium"}Here, the server separately addsrequestId,receivedAt,customerId, andneedsHumanReview. In particular,needsHumanReviewis not determined by model confidence alone. Sensitive intents such as refunds, personal information, and payment failures can be sent for review even if the confidence level is high.
A failure is to make your schema too large too quickly. If you receivedepartment,assignee,refundAmount,legalRisk, andreplyDraftat once from the beginning, it is easy to mix up the business meaning even if the model format matches. Separating the classification schema and the answer draft schema reduces the scope for failure. Even if the classification is incorrect, answer generation may not start, and even if the answer draft fails, a classification log may be left.
The comparison criteria are simple. What Structured Outputs guarantees is that “the response is close to the schema shape.” What the service must guarantee is that “the value matches the current user, permissions, DB state, and policy.” Separating the two prevents you from running the wrong subsequent API just because you received JSON.
10. Q&A
Q1. If I use Structured Outputs, can I avoid using validation code?
no. Validation still needs to be done in the backend. It is fundamental not to trust external system results.
Q2. Should all LLM responses be JSON?
no. The final answer you show your users might be Markdown. However, it is a good idea to structure the values that the system must subsequently process.
Q3. What if my schema gets too big?
It's better to break it down into smaller pieces. Separate the extraction, classification, response, and review needs into step-by-step schemas rather than putting them into one large schema.
11. References and uncertainty
References
- OpenAI Structured Outputs:https://platform.openai.com/docs/guides/structured-outputs
- JSON Schema:https://json-schema.org/
- Pydantic:https://docs.pydantic.dev/
uncertainty
- Supported models and detailed API parameters may change over time.
- Performance and failure rates of complex schemas require real-world testing.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.