비용, 지연, 정합성 사이의 균형 잡기
이 글에서는 Redis Cache Aside 패턴으로 LLM 응답 캐시를 설계하는 방법을 정리합니다.
LLM 서비스는 일반 API보다 캐시의 효과가 클 수 있습니다. 같은 질문, 같은 문서, 같은 프롬프트 버전으로 반복 요청이 들어오면 매번 모델을 호출할 필요가 없습니다. 모델 호출을 줄이면 지연 시간도 줄고, 비용도 줄고, provider rate limit 압박도 완화됩니다.
하지만 LLM 응답 캐시는 위험할 수도 있습니다. 사용자 권한이 다른 문서의 답변을 잘못 재사용할 수 있고, 오래된 문서 기반 답변을 계속 보여줄 수 있고, 개인정보가 포함된 응답을 저장할 수도 있습니다.
분석 기준일: 2026-05-12
실습 기준 환경: FastAPI, Redis, PostgreSQL, OpenAI API
주요 참고자료: Redis Query Caching, Redis TTL/Eviction Docs, OpenAI Prompt Caching Docs
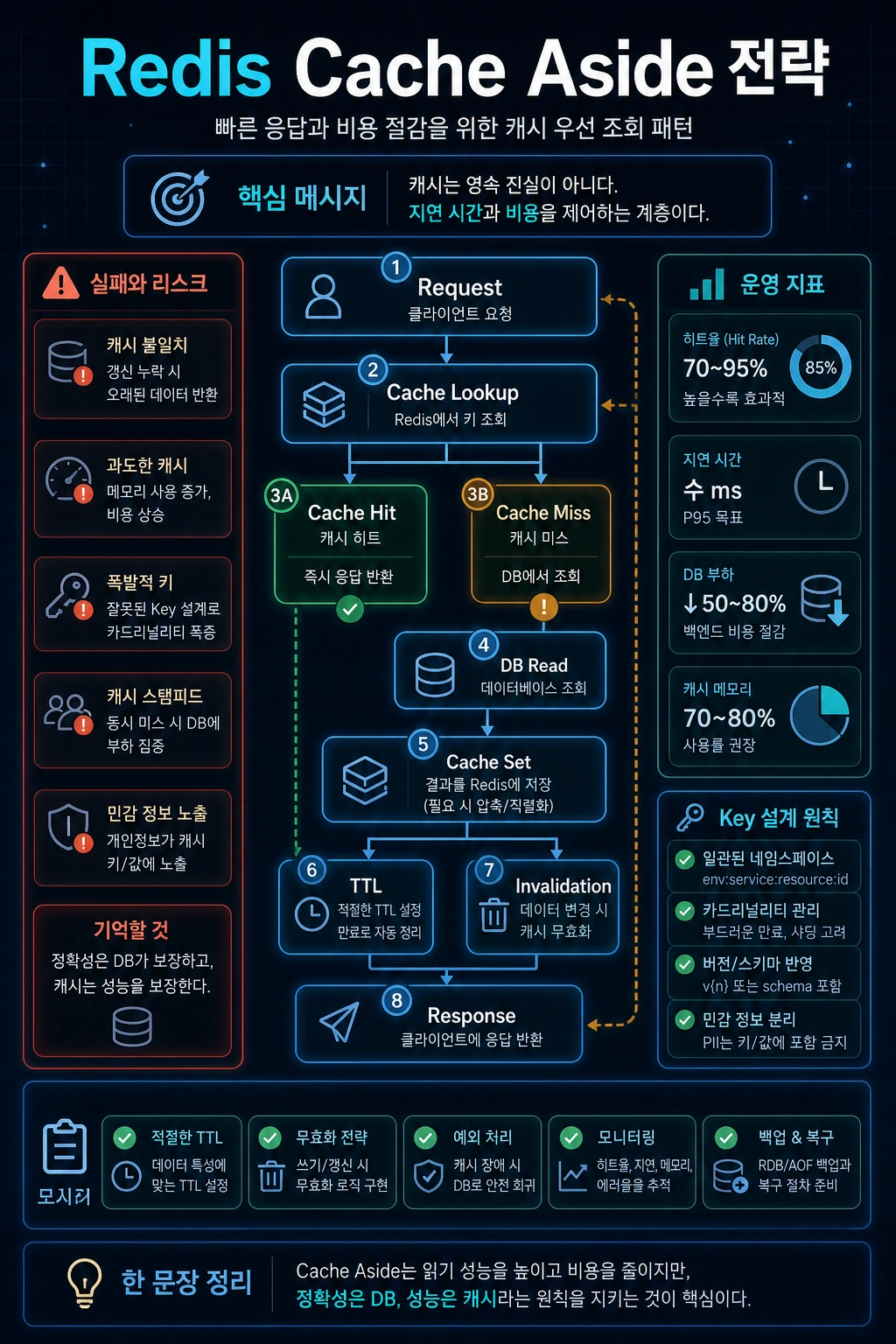
핵심 요약
- Cache Aside는 먼저 Redis를 조회하고, miss 시 원본 작업을 수행한 뒤 Redis에 저장하는 패턴이다.
- LLM 응답 캐시는
질문 + 문서 범위 + prompt version + model + 권한 범위를 함께 고려해야 한다. - 개인정보나 권한 의존 응답은 캐시하면 위험하다.
- TTL은 최신성, 비용, 사용자 경험 사이의 타협이다.
- cache hit rate, saved tokens, latency reduction을 지표로 남겨야 한다.
1. LLM 응답 캐시는 왜 필요한가
LLM 호출은 세 가지 비용을 만듭니다.
| 비용 | 설명 |
|---|---|
| 지연 비용 | 모델 응답까지 수 초가 걸릴 수 있음 |
| 금전 비용 | input/output token 비용 발생 |
| 운영 비용 | rate limit, timeout, provider 장애 대응 필요 |
동일하거나 유사한 요청이 반복되는 서비스라면 캐시는 매우 효과적입니다. 예를 들어 공식문서 Q&A, 에러 메시지 해설, 제품 정책 안내, 반복적인 요약 작업은 캐시 후보가 될 수 있습니다.
2. Cache Aside 패턴 흐름
Cache Aside의 기본 흐름은 단순합니다.
# 예시입니다.1. 요청을 받는다.2. cache key를 만든다.3. Redis에서 key를 조회한다.4. hit이면 cached response를 반환한다.5. miss이면 LLM을 호출한다.6. 응답을 검증한다.7. Redis에 TTL과 함께 저장한다.8. 응답을 반환한다.이 패턴의 장점은 애플리케이션이 캐시 정책을 직접 제어한다는 점입니다. 단점은 캐시 키와 무효화 정책을 잘못 설계하면 데이터가 틀릴 수 있다는 점입니다.
3. Cache Key 설계
LLM 응답 캐시의 핵심은 key입니다. 질문 텍스트만 key로 쓰면 안 됩니다.
# 예시입니다.llm:answer:{hash(question + document_scope + prompt_version + model + user_acl_scope)}| 구성 요소 | 필요한 이유 |
|---|---|
| question | 사용자의 질문 |
| document_scope | 어떤 문서 집합을 검색했는지 |
| prompt_version | 프롬프트 변경 시 캐시 분리 |
| model | 모델별 응답 차이 분리 |
| user_acl_scope | 권한이 다른 사용자 간 응답 오염 방지 |
| retrieval_version | 색인/검색 로직 변경 반영 |
예시:
# 예시 코드입니다.import hashlibimport json # 이 선언은 예시 흐름을 보여줍니다.def make_cache_key(payload: dict) -> str: normalized = json.dumps(payload, sort_keys=True, ensure_ascii=False) digest = hashlib.sha256(normalized.encode("utf-8")).hexdigest() return f"llm:answer:{digest}"4. TTL과 Invalidation
TTL은 캐시의 생존 시간입니다. LLM 응답 캐시에서는 TTL을 너무 길게 잡으면 오래된 답변이 남고, 너무 짧게 잡으면 캐시 효과가 사라집니다.
| 응답 유형 | TTL 후보 | 이유 |
|---|---|---|
| 공식문서 기반 답변 | 1시간–1일 | 문서 변경 주기에 따라 조정 |
| 자주 바뀌는 정책 답변 | 짧게 또는 캐시 금지 | 최신성 중요 |
| 사용자 개인 데이터 답변 | 캐시 금지 또는 사용자별 캐시 | 권한/개인정보 위험 |
| 코드 예제 설명 | 수 시간–수일 | 비교적 안정적 |
문서가 변경되면 관련 캐시를 무효화해야 합니다. 단순 TTL만으로는 변경 직후 오래된 답변이 나갈 수 있습니다.
5. 캐시하면 안 되는 응답
LLM 응답이라고 모두 캐시하면 안 됩니다.
보안 주의
사용자의 개인정보, 내부 문서 전문, 권한이 제한된 데이터, 의료·금융·법률처럼 최신성과 정확성이 중요한 답변은 캐시 정책을 매우 보수적으로 설계해야 합니다.
캐시 금지 후보는 다음과 같습니다.
# 예시입니다.[ ] 사용자별 민감 정보가 포함된 답변[ ] 권한에 따라 문서 접근 결과가 달라지는 답변[ ] 실시간 데이터 기반 답변[ ] 최신 공지, 가격, 정책처럼 자주 바뀌는 정보[ ] 모델이 불확실하다고 표시한 답변6. Cache Stampede 대응
캐시가 동시에 만료되면 많은 요청이 한꺼번에 LLM을 호출할 수 있습니다. 이를 cache stampede라고 볼 수 있습니다.
대응 방법은 다음과 같습니다.
| 방법 | 설명 |
|---|---|
| Lock | 같은 key에 대해 한 요청만 LLM 호출 |
| Random TTL | 만료 시점을 분산 |
| Early Refresh | 만료 전 백그라운드 갱신 |
| Stale-While-Revalidate | 오래된 값을 잠깐 반환하고 뒤에서 갱신 |
초기 구현에서는 lock과 random TTL만으로도 효과가 있습니다.
7. FastAPI + Redis 예제
# 예시 코드입니다.from fastapi import FastAPIimport redis.asyncio as redisimport json app = FastAPI()r = redis.Redis(host="localhost", port=6379, decode_responses=True) @app.post("/answers")# 이 선언은 예시 흐름을 보여줍니다.async def create_answer(req: dict): cache_payload = { "question": req["question"], "document_scope": req.get("document_scope"), "prompt_version": "answer.v1", "model": "configured-model-name", } cache_key = make_cache_key(cache_payload) cached = await r.get(cache_key) if cached: return {"source": "cache", "data": json.loads(cached)} answer = await call_llm_and_validate(req) await r.set(cache_key, json.dumps(answer, ensure_ascii=False), ex=3600) return {"source": "llm", "data": answer}이 코드는 구조를 보여주기 위한 예시입니다. 실제 서비스에서는 권한 범위, 개인정보 마스킹, timeout, retry, tracing을 추가해야 합니다.
8. 운영 지표 설계
캐시는 붙였는지가 아니라 효과가 있는지가 중요합니다.
| 지표 | 의미 |
|---|---|
llm_cache_hit_rate | 캐시 적중률 |
llm_cache_saved_tokens | 절약한 input/output token 추정치 |
llm_cache_latency_saved_ms | 절약한 지연 시간 |
llm_cache_key_cardinality | key 다양성 |
llm_cache_stale_response_count | 오래된 응답 발생 수 |
캐시 hit rate가 낮다면 key가 너무 세분화되었거나, 요청 패턴이 캐시에 맞지 않는 것일 수 있습니다.
9. 실무 체크리스트
# 예시입니다.[ ] 캐시 가능한 응답과 금지 응답을 분류했는가?[ ] cache key에 prompt_version과 model이 포함되어 있는가?[ ] 사용자 권한 범위를 key에 반영했는가?[ ] TTL 기준을 문서 변경 주기와 연결했는가?[ ] 문서 변경 시 invalidation 전략이 있는가?[ ] cache stampede 대응이 있는가?[ ] 캐시 hit rate와 saved tokens를 측정하는가?[ ] Redis 장애 시 DB/LLM fallback 경로가 있는가?10. Q&A
Q1. Prompt Caching과 Redis 응답 캐시는 같은 건가요?
아닙니다. Prompt Caching은 provider가 반복 prompt prefix 계산을 재사용하는 방식이고, Redis 응답 캐시는 애플리케이션이 최종 응답을 저장하는 방식입니다. 둘은 함께 사용할 수 있습니다.
Q2. 의미가 비슷한 질문도 캐시할 수 있나요?
가능하지만 위험도가 높습니다. semantic cache는 유사도 임계값과 오답 리스크를 함께 관리해야 하므로 초기에는 exact cache부터 시작하는 편이 안전합니다.
Q3. LLM 응답 캐시는 DB에도 저장해야 하나요?
대화 이력이나 감사 로그가 필요하면 DB에 저장합니다. Redis는 빠른 재사용 목적이고, DB는 이력과 분석 목적입니다.
11. 참고자료와 불확실성
참고자료
- Redis Query Caching: https://redis.io/tutorials/howtos/solutions/microservices/caching/
- Redis Docs: https://redis.io/docs/latest/
- OpenAI Prompt Caching: https://platform.openai.com/docs/guides/prompt-caching
불확실성
- 캐시 TTL은 서비스 도메인과 데이터 변경 주기에 따라 달라집니다.
- LLM provider의 prompt caching 정책은 모델과 시점에 따라 달라질 수 있습니다.
- semantic cache는 별도의 품질 평가가 필요합니다.
운영 예시: 캐시하면 안 되는 LLM 응답
Redis Cache Aside는 비용을 줄이지만 모든 응답에 적용하면 위험합니다. 개인 문서 요약, 계정 상태, 결제 정보, 최신 공시처럼 사용자별 또는 시간 의존성이 강한 답변은 캐시 범위를 좁혀야 합니다. cache key에는 prompt version, model, tenant, 권한 scope, 입력 hash가 들어가야 하고 개인정보 원문은 들어가면 안 됩니다.
| 응답 유형 | 캐시 판단 | 이유 |
|---|---|---|
| 공개 문서 FAQ | 가능 | 입력과 권한이 안정적 |
| 개인 문서 요약 | 제한적 | 사용자별 권한 필요 |
| 결제 상태 답변 | 보통 금지 | 민감정보와 최신성 문제 |
| 실시간 가격 해석 | 금지 또는 매우 짧은 TTL | 데이터가 빠르게 바뀜 |
실패 사례는 의미가 비슷한 질문을 같은 cache key로 묶는 경우입니다. "환불 가능해?"와 "환불 절차 알려줘"는 비슷해 보여도 답변 범위가 다릅니다. semantic cache는 비용을 줄일 수 있지만 잘못된 답을 재사용할 위험도 큽니다. 초기에는 deterministic key로 시작하고, cache hit ratio와 오답 신고를 본 뒤 범위를 넓히는 편이 안전합니다.
Balancing Cost, Delay, and Consistency
This article summarizes how to design an LLM response cache using the Redis Cache Aside pattern.
LLM services may benefit from greater caching than regular APIs. If repeated requests come in with the same question, same document, or same prompt version, there is no need to call the model each time. Reducing model calls reduces latency, reduces costs, and relieves provider rate limit pressure.
However, the LLM response cache can also be dangerous. User permissions may incorrectly reuse answers from other documents, continue to show outdated document-based answers, and even store responses that contain personal information.
Analysis date: 2026-05-12 Practice environment: FastAPI, Redis, PostgreSQL, OpenAI API Main reference materials: Redis Query Caching, Redis TTL/Eviction Docs, OpenAI prompt caching Docs
Key takeaways
- Cache Aside is a pattern that first queries Redis, performs the original task in case of a miss, and then stores it in Redis.
- The LLM response cache must consider ‘question + document scope + prompt version + model + authority scope’ together.
- It is dangerous to cache personal information or authority-dependent responses.
- TTL is a compromise between freshness, cost, and user experience.
- Cache hit rate, saved tokens, and latency reduction should be used as indicators.
1. Why do you need LLM response cache?
LLM calls create three costs:
| expense | explanation |
|---|---|
| delay cost | It may take several seconds for the model to respond |
| monetary expenses | Input/output token cost incurred |
| operating costs | Rate limit, timeout, provider failure response required |
Cache is very effective for services where the same or similar requests are made repeatedly. For example, official document Q&A, error message explanations, product policy information, and repetitive summary tasks can be cache candidates.
2. Cache Aside pattern flow
The basic flow of Cache Aside is simple.
# This is an example.1. Receive a request.2. Create a cache key.3. Search the key in Redis.4. If it is a hit, a cached response is returned.5. If it is a miss, call LLM.6. Verify the response.7. Save it with TTL in Redis.8. Return the response.The advantage of this pattern is that the application directly controls the cache policy. The downside is that poorly designed cache keys and invalidation policies can result in incorrect data.
3. Cache Key Design
The core of the LLM response cache is the key. Do not use only the question text as the key.
# This is an example.llm:answer:{hash(question + document_scope + prompt_version + model + user_acl_scope)}| component | Why you need it |
|---|---|
| question | User's Questions |
| document_scope | Which document set was searched |
| prompt_version | Disconnect cache when prompt changes |
| model | Isolate response differences by model |
| user_acl_scope | Prevent response contamination between users with different permissions |
| retrieval_version | Reflection of index/search logic changes |
example:
# This is example code.import hashlibimport json # This declaration shows an example flow.def make_cache_key(payload: dict) -> str: normalized = json.dumps(payload, sort_keys=True, ensure_ascii=False) digest = hashlib.sha256(normalized.encode("utf-8")).hexdigest() return f"llm:answer:{digest}"4. TTL and Invalidation
TTL is the cache survival time. In the LLM response cache, if the TTL is too long, old answers will remain, and if the TTL is too short, the cache effect will disappear.
| response type | TTL candidate | reason |
|---|---|---|
| Answer based on official documents | 1 hour to 1 day | Adjust according to document change cycle |
| Frequently changing policy answers | short or no cache | Recency is important |
| User Personal Data Reply | Disable cache or per-user cache | Permissions/Privacy Risks |
| Code Example Description | Hours to days | relatively stable |
When a document changes, the associated cache must be invalidated. A simple TTL may cause out-of-date answers to appear immediately after a change.
5. Responses that should not be cached
All LLM responses should not be cached.
Security Caution Cache policies should be designed very conservatively for answers where up-to-dateness and accuracy are important, such as user personal information, full text of internal documents, data with limited rights, and medical, financial, and legal information.
Candidates for banning caches include:
# This is an example.[ ] Answers containing sensitive information for each user[ ] Answer that document access results vary depending on permissions[ ] Real-time data-based answer[ ] Frequently changing information such as latest notices, prices, and policies[ ] Responses indicating that the model is uncertain6. Cache Stampede response
If caches expire at the same time, many requests may call LLM at once. This can be viewed as a cache stampede.
Here's how to respond:
| method | explanation |
|---|---|
| Lock | Only one request for the same key calls LLM |
| Random TTL | Distribute expiration points |
| Early Refresh | Background renewal before expiration |
| Stale-While-Revalidate | Briefly return the old value and update it later |
In initial implementations, just lock and random TTL will work.
7. FastAPI + Redis example
# This is example code.from fastapi import FastAPIimport redis.asyncio as redisimport json app = FastAPI()r = redis.Redis(host="localhost", port=6379, decode_responses=True) @app.post("/answers")# This declaration shows an example flow.async def create_answer(req: dict): cache_payload = { "question": req["question"], "document_scope": req.get("document_scope"), "prompt_version": "answer.v1", "model": "configured-model-name", } cache_key = make_cache_key(cache_payload) cached = await r.get(cache_key) if cached: return {"source": "cache", "data": json.loads(cached)} answer = await call_llm_and_validate(req) await r.set(cache_key, json.dumps(answer, ensure_ascii=False), ex=3600) return {"source": "llm", "data": answer}This code is an example to demonstrate the structure. In an actual service, permission scope, personal information masking, timeout, retry, and tracing must be added.
8. Operational indicator design
The important thing about cache is not whether it is attached, but whether it is effective.
| characteristic | meaning |
|---|---|
llm_cache_hit_rate | cache hit rate |
llm_cache_saved_tokens | Savings input/output token estimate |
llm_cache_latency_saved_ms | Latency saved |
llm_cache_key_cardinality | key diversity |
llm_cache_stale_response_count | Number of stale response occurrences |
If the cache hit rate is low, the key may be too granular or the request pattern may not fit the cache.
9. Practical checklist
# This is an example.[ ] Have you classified cacheable and prohibited responses?[ ] Are prompt_version and model included in the cache key?[ ] Has the scope of user authority been reflected in the key?[ ] Are the TTL criteria linked to the document change cycle?[ ] Is there an invalidation strategy when changing documents?[ ] Is there a cache stampede response?[ ] Do you measure cache hit rate and saved tokens?[ ] Is there a DB/LLM fallback path in case of Redis failure?10. Q&A
Q1. Are prompt caching and Redis response cache the same?
no. prompt caching is a way for providers to reuse repeated prompt prefix calculations, and Redis response cache is a way for applications to store final responses. The two can be used together.
Q2. Can questions with similar meaning be cached?
It's possible, but the risk is high. Since the semantic cache must manage both the similarity threshold and the risk of wrong answers, it is safer to start with the exact cache initially.
Q3. Should the LLM response cache be stored in the DB as well?
If you need conversation history or audit logs, save them in the DB. Redis is for quick reuse, and DB is for history and analysis purposes.
11. References and uncertainty
References
- Redis Query Caching:https://redis.io/tutorials/howtos/solutions/microservices/caching/
- Redis Docs:https://redis.io/docs/latest/
- OpenAI prompt caching:https://platform.openai.com/docs/guides/prompt-caching
uncertainty
- Cache TTL depends on the service domain and data change cycle.
- An LLM provider's prompt caching policy may vary depending on the model and timing.
- Semantic cache requires separate quality evaluation.
Operational example: LLM responses that should not be cached
Redis Cache Aside reduces costs, but applying it to every response is risky. Responses that are highly user-specific or time-dependent, such as personal document summaries, account status, payment information, and latest disclosures, may require narrow cache coverage. The cache key must contain prompt version, model, tenant, permission scope, and input hash, and must not contain the original text of personal information.
| response type | cache judgment | reason |
|---|---|---|
| Public Document FAQs | possible | Input and permissions are stable |
| Personal document summary | limited | Requires user-specific permissions |
| Payment status reply | Usually prohibited | Sensitive information and recency issues |
| Real-time price analysis | Prohibited or very short TTL | Data changes quickly |
A failure case is when questions with similar meaning are grouped with the same cache key. “Is it possible to get a refund?” and “Please tell me the refund process” may seem similar, but the scope of the answer is different. A semantic cache can reduce costs, but it also carries a high risk of reusing incorrect answers. It is safer to start with a deterministic key initially and expand the range after looking at the cache hit ratio and incorrect answer reports.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.