
이번 글은 “코딩 에이전트 런타임 설계” 시리즈의 마지막 편입니다. 앞선 글에서는 런타임 관점, Goal Contract, A2A와 MCP, AI Memory와 Run Ledger를 다뤘습니다.
이번에는 이론을 실제 개발 하네스 문서 세트로 옮깁니다. 목표는 단순합니다. 팀이 당장 거대한 agent runtime을 만들지 않더라도, 에이전트에게 맡길 작업의 경계와 산출물은 파일로 고정할 수 있어야 합니다.
AI 에이전트가 오래 일해도 안전하도록, 작업 계약과 산출물 계약을 파일로 분리한다.
핵심 요약
- 처음부터 거대한 agent runtime을 만들 필요는 없습니다.
- MVP는 문서 기반 하네스로 시작해도 충분합니다.
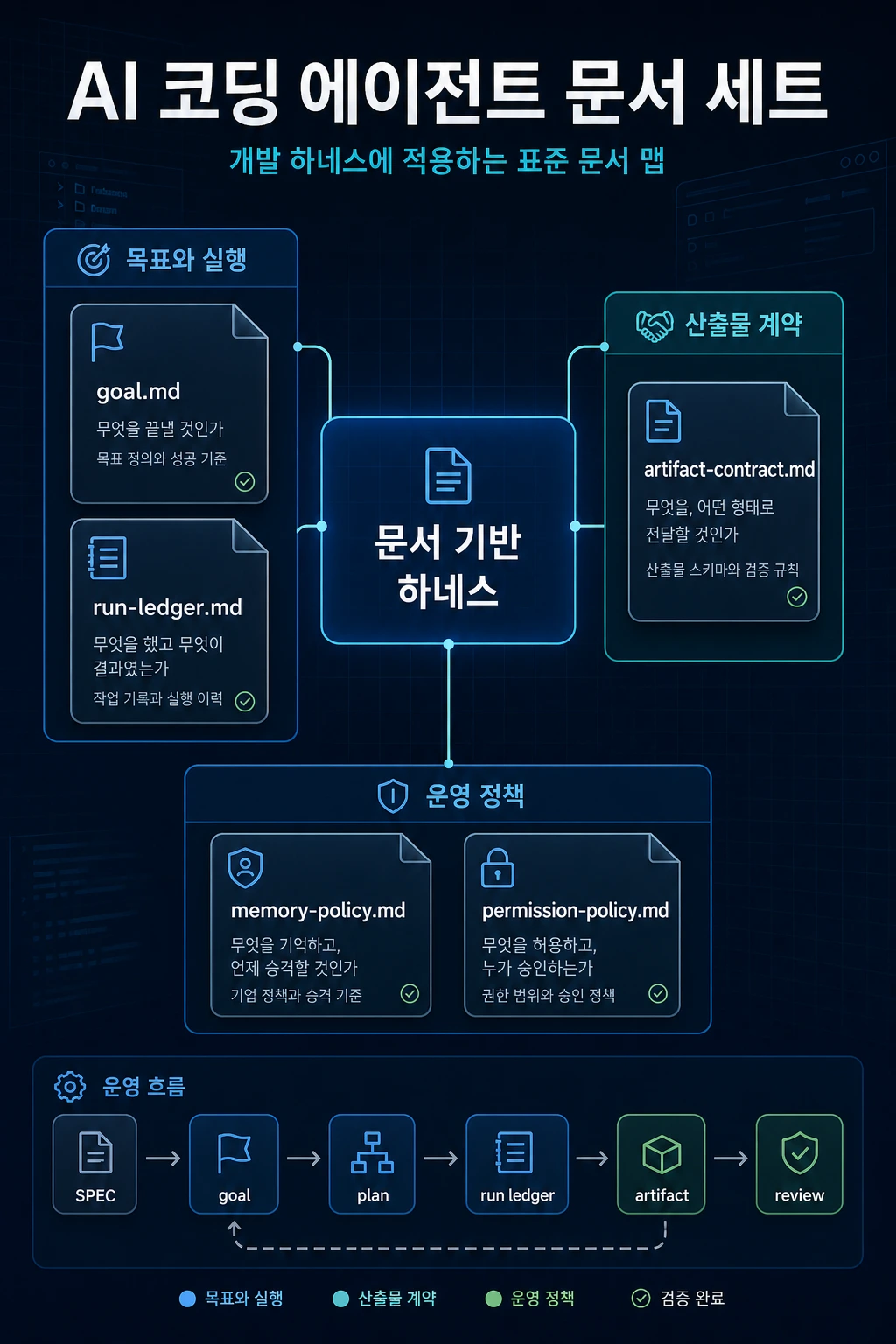
- 최소 문서 세트는
goal.md,run-ledger.md,artifact-contract.md,memory-policy.md,permission-policy.md입니다. - 이 문서들은 에이전트에게 무엇을 할지뿐 아니라 어디서 멈출지와 무엇을 남길지를 알려줍니다.
- 나중에 필요해지면 이 문서 구조를 SQLite나 runtime state로 승격할 수 있습니다.
왜 문서 세트로 시작하는가
개발 하네스를 만들 때 처음부터 복잡한 시스템을 만들고 싶어질 수 있습니다.
SQLite stateagent schedulermulti-agent orchestratortask queuememory graphvector databasepermission engine이런 구조는 언젠가 필요할 수 있습니다. 하지만 MVP 단계에서는 너무 무겁습니다. 처음에는 파일 기반 문서 세트로 충분합니다.
| 이유 | 설명 |
|---|---|
| 사람이 읽기 쉽다 | 에이전트가 한 일을 바로 검토 가능 |
| git으로 추적 가능 | 변경 이력을 확인 가능 |
| 도구 독립적 | Claude Code, Codex, Cursor 등과 함께 사용 가능 |
| 점진적 확장 가능 | 나중에 DB나 runtime state로 승격 가능 |
| 실패 분석 가능 | 대화가 아니라 산출물로 남음 |
OpenAI의 Codex harness 글은 여러 Codex surface가 동일한 harness와 App Server를 통해 agent loop를 공유한다고 설명합니다. 직접 App Server를 구현하지 않더라도, agent loop, thread state, approval, diff event 같은 개념은 운영 문서로 흡수할 수 있습니다.
추천 디렉터리 구조
MVP 구조는 다음처럼 시작할 수 있습니다.
.agent-runtime/ goals/ profile-update/ goal.md plan.md run-ledger.md artifacts/ changed-files.md test-result.md risk-summary.md policies/ artifact-contract.md memory-policy.md permission-policy.md memory/ candidates/ validated/핵심은 분리입니다. 문서 세트를 역할별로 나누면 에이전트가 목표, 실행 기록, 산출물, 정책을 같은 말로 섞지 않습니다.
goal.md 템플릿
첫 파일은 목표, 범위, 완료 조건, 중단 조건을 한곳에 묶는 계약입니다.
Goal: Metadata: goal_id: created_at: owner: status: draft | in_progress | blocked | completed | cancelled Objective: 이 goal의 최종 목표를 한 문장으로 작성한다. Context: 왜 이 작업이 필요한지, 현재 상태는 어떤지 정리한다. Scope: In Scope: - 포함할 작업 Out of Scope: - 제외할 작업 Done Criteria: - 관찰 가능한 완료 조건 - 테스트 또는 검증 명령 - 사용자 관점의 완료 기준 - 마지막에 남길 요약 기준 Stop Conditions: - DB schema 변경 필요 시 중단 - 인증/권한 로직 변경 필요 시 중단 - 외부 비용 발생 시 중단 - secret 접근 필요 시 중단 - production 배포 필요 시 중단 Artifact Contract: - 변경 파일 목록 - 핵심 변경 요약 - 실행한 검증 명령 - 실패한 검증과 이유 - 남은 리스크 Notes: - 추가 참고사항이 파일은 에이전트에게 가장 먼저 읽혀야 합니다. 목표와 중단 조건이 없는 장시간 실행은 운영 리스크가 큽니다.
run-ledger.md 템플릿
두 번째 파일은 에이전트의 실제 실행 이력을 task attempt 단위로 남기는 기록입니다.
Run Ledger Entry: task_id: attempt_id: started_at: input: - 참고한 파일 - 참고한 문서 - 실행한 명령 action: - 수행한 변경 - 실행한 테스트 - 검토한 내용 result: success | failed | blocked | input_required evidence: - diff - test log - error message - screenshot - command output diagnosis: 실패 또는 결과에 대한 해석 next_action: 다음 시도 방향 artifact_created: - artifact 파일 경로 memory_decision: none | candidate | validated human_review_required: yes | noRun Ledger는 에이전트의 작업 일지입니다. 대화 로그를 보지 않아도 어떤 일을 했는지 알 수 있어야 합니다.
artifact-contract.md 템플릿
세 번째 파일은 작업 결과를 대화 응답이 아니라 검토 가능한 산출물로 고정하는 기준입니다.
Artifact Contract: Implementation Artifact: - 변경 파일 목록 - 핵심 변경 내용 - 실행한 검증 명령 - 통과한 검증 - 실패한 검증 - 남은 리스크 - 사람이 확인해야 할 부분 Test Artifact: - 추가한 테스트 - 수정한 테스트 - 실행한 명령 - 통과/실패 결과 - 실패 재현 방법 - flaky 가능성 Review Artifact: result_levels: - blocker - warning - suggestion - verified - not_verified Failure Artifact: - 실패한 접근 - 실패 원인 - 증거 로그 - 버린 가정 - 다음 시도 제안 - memory 승격 여부Artifact Contract는 마지막 응답을 예쁘게 쓰라는 문서가 아닙니다. 검토 가능한 결과물을 남기라는 계약입니다.
memory-policy.md 템플릿
네 번째 파일은 무엇을 다음 작업의 전제로 남길지, 무엇을 버릴지 정하는 필터입니다.
Memory Policy: Store: - 반복적으로 필요한 build/test command - 코드베이스 구조상 중요한 convention - 여러 파일이 함께 변경되어야 하는 coupling - 두 번 이상 반복된 debugging insight - 현재 branch에서 검증된 workaround Do Not Store: - 일회성 오류 - 개인 정보 - API key, token, secret - 검증되지 않은 추측 - 특정 브랜치에만 존재하는 임시 상태 - 사용자의 일시적 요청 Validate Before Use: - 참조 파일이 현재 브랜치에 존재하는가 - package.json, README, CI config와 충돌하지 않는가 - 오래된 memory는 재검증했는가 - 적용 범위가 현재 task와 맞는가 Memory Metadata: - source - scope - validated_at - expires_at - ownerGitHub Copilot Memory 문서가 citation과 현재 branch 검증, stale memory 삭제를 강조하는 이유도 같은 맥락입니다. memory는 다음 작업의 전제가 되므로 검증과 만료가 필요합니다.
permission-policy.md 템플릿
마지막 파일은 에이전트가 직접 해도 되는 일과 사람 승인이 필요한 일을 나누는 통제면입니다.
Permission Policy: Allowed Without Approval: - read source files - edit non-sensitive source files - run unit tests - run lint - run typecheck - inspect git diff Approval Required: - add dependency - modify DB migration - change auth logic - change payment logic - modify CI/CD workflow - call external paid API - run e2e test against external service - update production-like config Blocked: - read env files - print secrets - access production DB - deploy to production - run destructive command - delete user data - bypass tests여기서 중요한 것은 permission policy가 instruction과 다르다는 점입니다. Instruction은 에이전트에게 이렇게 행동하라고 말합니다. Permission은 실제로 이것은 못 하게 막는 계층입니다.
Claude Code memory 문서가 memory를 context로 설명하는 것도 같은 이유입니다. 보안과 권한은 별도 정책과 실행 레이어에서 처리해야 합니다.
MVP 운영 플로우
문서 세트는 작성만 해서는 효과가 없습니다. 에이전트가 작업을 시작하기 전, 실행 중, 완료 후에 어느 파일을 읽고 갱신할지 순서를 고정해야 합니다.
- PRD / SPEC / UI
- goal.md 생성
- plan.md 작성
- 사람이 계획과 중단 조건 확인
- task 단위 실행
- run-ledger.md 기록
- artifacts 저장
- memory candidate 검토
- summary artifact 생성
이 흐름의 장점은 단순합니다. 실패해도 추적 가능합니다. 에이전트가 어디서 틀렸는지, 어떤 가정을 버렸는지, 어떤 테스트를 실행했는지, 다음 작업에 무엇을 기억해야 하는지 남습니다.
확장 방향
파일 기반 MVP가 안정화되면 다음 단계로 확장할 수 있습니다.
| 단계 | 구조 |
|---|---|
| MVP | Markdown 파일 기반 |
| V1 | JSON schema와 validation 추가 |
| V2 | SQLite runtime state 추가 |
| V3 | task scheduler와 approval queue 추가 |
| V4 | A2A 호환 agent delegation |
| V5 | memory graph와 repository별 validated memory |
처음부터 V5를 만들 필요는 없습니다. 가장 중요한 것은 작업 단위가 남는 구조입니다.
Goal 없이 작업하면 방향을 잃는다.Run Ledger 없이 작업하면 실패를 반복한다.Artifact 없이 작업하면 검토할 수 없다.Memory Policy 없이 작업하면 기억이 오염된다.Permission Policy 없이 작업하면 위험해진다.최종 체크리스트
하네스를 실제 프로젝트에 적용하기 전에는 아래 항목을 최소 운영 기준으로 삼으면 됩니다.
[ ] PRD / SPEC / UI 문서가 준비되어 있다.[ ] goal.md에 Objective와 Done Criteria가 있다.[ ] Stop Conditions가 위험 작업을 포함한다.[ ] run-ledger.md에 task attempt가 기록된다.[ ] artifact-contract.md가 있다.[ ] 테스트 결과와 실패 로그가 artifact로 남는다.[ ] memory-policy.md가 있다.[ ] memory 승격 기준이 있다.[ ] permission-policy.md가 있다.[ ] secret, production, deploy 작업은 차단된다.[ ] 사람이 최종 승인하는 흐름이 있다.마무리
코딩 에이전트는 점점 더 강력해지고 있습니다. 하지만 강력한 에이전트를 안전하게 쓰려면 모델보다 먼저 런타임을 설계해야 합니다.
프롬프트는 시작점입니다. 하지만 제품 개발은 프롬프트만으로 끝나지 않습니다. 앞으로 중요한 것은 목표를 정의하고, 작업을 기록하고, 산출물을 분리하고, 기억을 검증하고, 권한을 통제하는 것입니다.
이것이 개발 하네스가 해야 할 일입니다.
이 시리즈에서 바로 가져갈 결론은 단순합니다. goal.md, run-ledger.md, artifact-contract.md, memory-policy.md, permission-policy.md를 분리하면 에이전트의 작업을 대화가 아니라 검토 가능한 운영 단위로 다룰 수 있습니다.
시리즈 이어 읽기
- 1편: 코딩 에이전트는 왜 런타임이 되는가
- 2편: Codex
/goal로 보는 목표 기반 개발 - 3편: A2A와 MCP로 보는 멀티 에이전트 개발 워크플로우
- 4편: AI Memory는 RAG가 아니다
- 5편: 개발 하네스에 적용하는 AI 코딩 에이전트 문서 세트
참고자료
- Unlocking the Codex harness: how we built the App Server
- About agentic memory for GitHub Copilot
- How Claude remembers your project
독자 적용 노트
이 글은 AI agent나 코딩 도구를 실제 개발 업무에 적용하려는 개발자가 개발 하네스에 적용하는 AI 코딩 에이전트 문서 세트이라는 주제를 단순 개념 설명이 아니라 AI 도구를 실제 작업 흐름에 붙일 때의 실행 경계로 점검하도록 작성했습니다. 본문에서 다룬 구조는 새 도구를 도입하거나 기존 워크플로우를 바꿀 때 "무엇을 먼저 확인해야 하는가"를 정하는 데 쓰는 것이 좋습니다.
원본 판단 근거
이 글의 판단은 왜 문서 세트로 시작하는가에서 설명한 구조와 본문 안의 예시, 표, 체크리스트를 함께 놓고 정리한 것입니다. 특히 독자가 그대로 복사할 수 있는 결론보다, 자신의 코드베이스나 팀 규칙에 맞춰 확인해야 할 경계와 실패 조건을 분리하는 데 초점을 둡니다.
실패 사례 또는 edge case
가장 흔한 실패는 AI 도구를 실제 작업 흐름에 붙일 때의 실행 경계를 문서나 명칭만 맞춘 상태로 끝내는 것입니다. 예를 들어 실제 입력, 권한, 로그, 배포, 검증 기준이 연결되지 않으면 겉으로는 도입이 끝난 것처럼 보여도 다음 작업에서 같은 문제가 반복됩니다. 따라서 본문을 적용할 때는 "누가 실행하는가", "무엇을 기록하는가", "실패하면 어디서 멈추는가"를 같이 확인해야 합니다.
실무 체크리스트
- 이 글의 핵심 개념을 현재 프로젝트의 실제 파일, API, 로그, 문서 중 하나에 연결했다.
- 본문 예시를 그대로 쓰지 않고 우리 환경의 제약 조건으로 다시 검토했다.
- 실패 사례나 edge case를 하나 이상 정하고, 재현 또는 확인 방법을 적었다.
- 적용 후 바뀌어야 할 완료 기준과 검증 명령을 분리했다.
Q&A
Q1. 이 글의 내용을 바로 표준으로 써도 되나요?
바로 표준으로 고정하기보다 작은 작업 하나에 먼저 적용해 보는 편이 안전합니다. 실제 로그, 리뷰, 테스트에서 같은 판단이 반복해서 맞을 때 팀 표준으로 올리는 것이 좋습니다.
Q2. 본문 예시와 내 프로젝트가 다르면 어떻게 해야 하나요?
예시의 이름보다 경계를 보세요. 입력, 상태, 권한, 검증, 기록 중 어떤 경계를 다루는 글인지 먼저 찾고, 그 경계를 현재 프로젝트의 구조에 맞게 옮기면 됩니다.
참고자료와 불확실성
이 보강 노트는 본문에 이미 포함된 참고자료와 작성 시점의 공개 문서를 기준으로 합니다. 도구 버전, API 정책, 제품 UI는 바뀔 수 있으므로 실제 적용 전에는 공식 문서와 현재 런타임 동작을 다시 확인해야 합니다.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.