
이 시리즈에서 보는 것
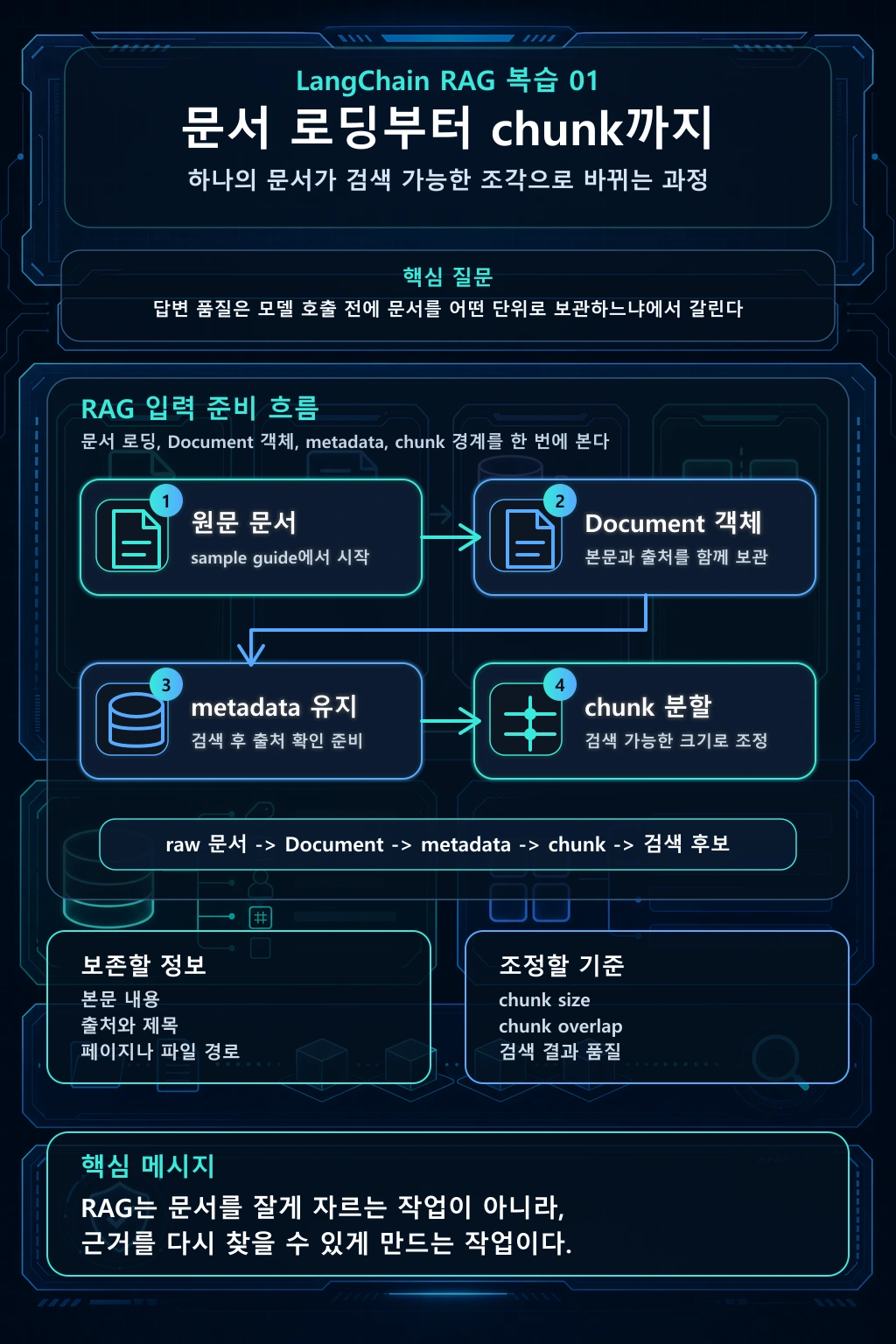
이 글은 LangChain RAG 학습 흐름 정리의 첫 글이다. 목표는 RAG를 한 번에 완성하는 것이 아니라, 하나의 예시 문서가 RAG 파이프라인 안에서 어떤 형태로 바뀌는지 차례대로 보는 것이다.
예시는 sample-office-guide.md라는 가상의 사내 지식 문서로 둔다. 회의실 예약, 장비 대여, 보안 출입 같은 짧은 안내가 들어 있는 문서라고 생각하면 된다. 실제 내부 문서가 아니라, 문서 로딩부터 검색까지 같은 아티팩트가 어떻게 변하는지 보기 위한 학습용 재료다.
첫 글에서 답변은 만들지 않는다. 질문을 던지고 모델이 답하는 장면은 아직 이르다. 먼저 문서가 Document가 되어야 하고, 그 Document가 검색 가능한 chunk로 나뉘어야 한다. 이 두 단계를 묶어 보면 RAG 초반부에서 가장 중요한 기준이 보인다. "무엇을 읽었는가", "그 출처를 잃지 않았는가", "검색 단위로 잘라도 의미가 남는가"다.
답변보다 먼저 남겨야 할 것
RAG를 처음 보면 질문과 답변에 눈이 간다. 하지만 실제 흐름의 시작점은 질문이 아니라 문서다. 문서를 읽고, 본문을 꺼내고, 출처 정보를 붙여 다음 단계가 이어받을 수 있는 형태로 만들어야 한다.
LangChain에서 이때 자주 보는 단위가 Document다. Document는 본문만 담는 상자가 아니다. page_content에는 검색 대상이 될 텍스트가 들어가고, metadata에는 나중에 출처를 되짚기 위한 정보가 들어간다.
from langchain_core.documents import Document raw_text = """예시 사내 지식 문서 회의실 예약은 사용 시작 1시간 전까지 가능합니다.회의실 사용 후에는 장비 상태를 확인해 주세요. 장비 대여는 안내 데스크에서 기록 후 반납합니다.보안 출입 카드는 승인된 대상만 신청할 수 있습니다.""".strip() doc = Document( page_content=raw_text, metadata={ "source": "sample-office-guide.md", "source_type": "markdown", "section": "office-guide", "version": "2026-06", },) print(doc.page_content)print(doc.metadata)이 출력에서 먼저 볼 것은 문장이 예쁘게 보이는지가 아니다. 본문과 추적 정보가 함께 남았는지다. page_content만 있고 metadata가 비어 있으면 나중에 검색 결과를 봐도 이 조각이 어디서 왔는지 설명하기 어렵다. 반대로 metadata만 그럴듯하고 본문 줄바꿈이 깨져 있으면 split 단계에서 제목과 본문이 엉뚱하게 나뉠 수 있다.
Document 출력에서 확인할 것
Document를 만들었으면 바로 다음 단계로 넘기기 전에 작은 출력을 읽어야 한다.
| 확인 항목 | 보는 이유 |
|---|---|
| 본문 | 문서 내용이 누락되거나 깨지지 않았는지 확인한다 |
| source | 나중에 검색 결과에서 파일 단위 출처를 되짚기 위해 필요하다 |
| section | 같은 파일 안에서도 어떤 영역에서 온 문장인지 구분한다 |
| version | 문서가 갱신됐을 때 오래된 index를 의심할 수 있다 |
| source_type | Markdown, PDF, 웹 문서처럼 처리 방식이 다른 입력을 구분한다 |
이 체크는 작아 보이지만 뒤에서 큰 차이를 만든다. retriever가 회의실 예약 문장을 잘 가져왔더라도 metadata가 없다면 "어느 문서의 어느 섹션을 근거로 답했는가"를 남기기 어렵다. RAG에서 출처 표시는 마지막 단계에서 갑자기 붙는 기능이 아니라 초반 metadata가 살아 있을 때 가능해진다.
그대로 임베딩하지 않는 이유
이제 sample-office-guide.md는 Document가 되었다. 여기서 바로 임베딩해도 실행은 될 수 있다. 하지만 문서 하나에 회의실 예약, 장비 대여, 보안 출입이 모두 들어 있다면 검색 단위가 너무 거칠다.
질문이 "회의실 예약은 언제까지 가능한가?"라면 장비 대여 문단과 보안 출입 문단은 답변에 필요하지 않다. 문서 전체를 하나의 벡터로 만들면 관련 없는 내용이 같이 검색될 수 있다. 반대로 너무 작게 자르면 "회의실 예약"이라는 문장만 남고 사용 시점이나 주의 문장이 떨어져 나갈 수 있다.
그래서 split은 단순히 길이를 줄이는 작업이 아니다. 질문이 들어왔을 때 답변 재료로 쓸 수 있는 단위로 문서를 다시 나누는 작업이다.
실행 예시: Document를 chunk로 나누기
아래 예시는 앞에서 만든 Document를 chunk로 나누고, 실제 출력이 어떤 모양인지 확인하는 흐름이다.
from langchain_text_splitters import RecursiveCharacterTextSplitter splitter = RecursiveCharacterTextSplitter( chunk_size=95, chunk_overlap=20, separators=["\n\n", "\n", " ", ""],) chunks = splitter.split_documents([doc]) for index, chunk in enumerate(chunks): print(f"chunk-{index}") print(chunk.page_content) print(chunk.metadata)여기서 중요한 것은 chunk_size=95라는 숫자 자체가 아니다. 출력된 chunk를 읽었을 때 회의실 예약 문장과 장비 상태 확인 문장이 어떤 관계로 남는지가 중요하다. 회의실 예약 질문에 답하려면 "사용 시작 1시간 전"이라는 조건이 같은 chunk 안에 있어야 한다. 그런데 보안 출입 카드 문장까지 같은 chunk에 들어오면 검색 결과에는 불필요한 소음이 섞인다.
chunk size와 overlap은 출력으로 판단한다
chunk_size와 chunk_overlap은 정답을 외우는 값이 아니다. 문서의 문장 길이, 제목 구조, 질문의 성격에 따라 다르게 봐야 한다.
| 보는 지점 | 좋은 신호 | 다시 볼 신호 |
|---|---|---|
| chunk 크기 | 질문에 필요한 문맥이 한 조각 안에 남는다 | 관련 없는 주제가 한 조각에 많이 섞인다 |
| 경계 | 제목과 본문이 함께 움직인다 | 제목만 떨어지거나 문장이 중간에서 잘린다 |
| overlap | 경계 근처 문맥이 이어진다 | 거의 같은 chunk가 반복된다 |
| metadata | 원래 Document의 출처가 유지된다 | chunk에서 source나 section이 사라진다 |
출력을 읽다 보면 split이 잘됐는지 빠르게 보인다. 제목만 따로 나온다면 separator나 chunk 크기를 다시 봐야 한다. 문장이 중간에서 잘리면 overlap이 부족하거나 분할 기준이 맞지 않을 수 있다. chunk가 너무 길면 다음 단계에서 retriever가 질문과 무관한 문장을 같이 가져올 가능성이 커진다.
경계 사례: 실패 신호는 초반에 잡는다
문서 로딩과 chunking에서 생긴 문제는 뒤에서 검색 품질 문제처럼 보인다. 그래서 이 단계의 실패 신호를 따로 봐야 한다.
- 본문이 비어 있다: loader나 인코딩 문제를 먼저 확인한다.
- 줄바꿈이 깨져 있다: Markdown 구조가 split에 불리하게 바뀌었을 수 있다.
- metadata가 없다: 나중에 출처 표시와 디버깅이 어려워진다.
- chunk가 제목만 담고 있다: 검색 단위로는 의미가 약하다.
- 같은 문장이 너무 많이 반복된다: overlap이 중복을 만들고 있을 수 있다.
- 서로 다른 주제가 한 chunk에 섞인다: 검색 결과에 불필요한 context가 따라온다.
이런 문제는 LLM으로 답변을 만들고 난 뒤에 찾으면 늦다. 모델이 그럴듯한 문장으로 덮어버리기 때문이다. RAG 초반부에서는 답변을 보지 말고 중간 산출물을 봐야 한다.
이 글에서 남은 아티팩트
여기까지 오면 손에 남는 것은 답변이 아니라 chunk 목록이다. 각 chunk에는 본문이 있고, metadata에는 sample-office-guide.md, 섹션, 버전 같은 단서가 붙어 있다.
이 상태가 다음 글의 시작점이다. 다음 단계에서는 이 chunk들을 embedding으로 바꾸고 vector store에 넣는다. 그리고 사용자의 질문이 들어왔을 때 retriever가 어떤 chunk를 다시 꺼내는지 확인한다.
중요한 기준은 계속 같다. 검색이 잘되는지 보기 전에, 검색할 재료가 제대로 남았는지 먼저 봐야 한다.
짧은 FAQ
Q. 문서가 짧으면 split을 생략해도 되나?
A. 아주 짧은 문서라면 생략할 수 있다. 다만 여러 주제가 섞여 있으면 길이가 짧아도 검색 단위로는 거칠 수 있다. 생략 여부는 문서 길이보다 질문에 필요한 맥락이 한 단위 안에 자연스럽게 남는지로 판단하는 편이 낫다.
Q. metadata는 어느 정도까지 남겨야 하나?
A. 최소한 source는 남겨야 한다. 가능하면 section, page, version처럼 나중에 검색 결과를 되짚을 수 있는 단서도 같이 남긴다. metadata는 장식이 아니라 검색 결과를 설명하는 근거다.
Q. chunk size를 먼저 정하고 시작해도 되나?
A. 시작값은 정할 수 있다. 하지만 결정은 출력된 chunk를 읽고 해야 한다. 숫자가 좋아 보여도 제목과 본문이 분리되거나 같은 문장이 반복되면 다시 조정해야 한다.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.