
chunk가 질문을 만나는 자리
앞 글에서 sample-office-guide.md는 Document가 되었고, 그 Document는 검색 가능한 chunk 목록으로 나뉘었다. 이제 질문이 들어오면 이 chunk들이 다시 선택되어야 한다.
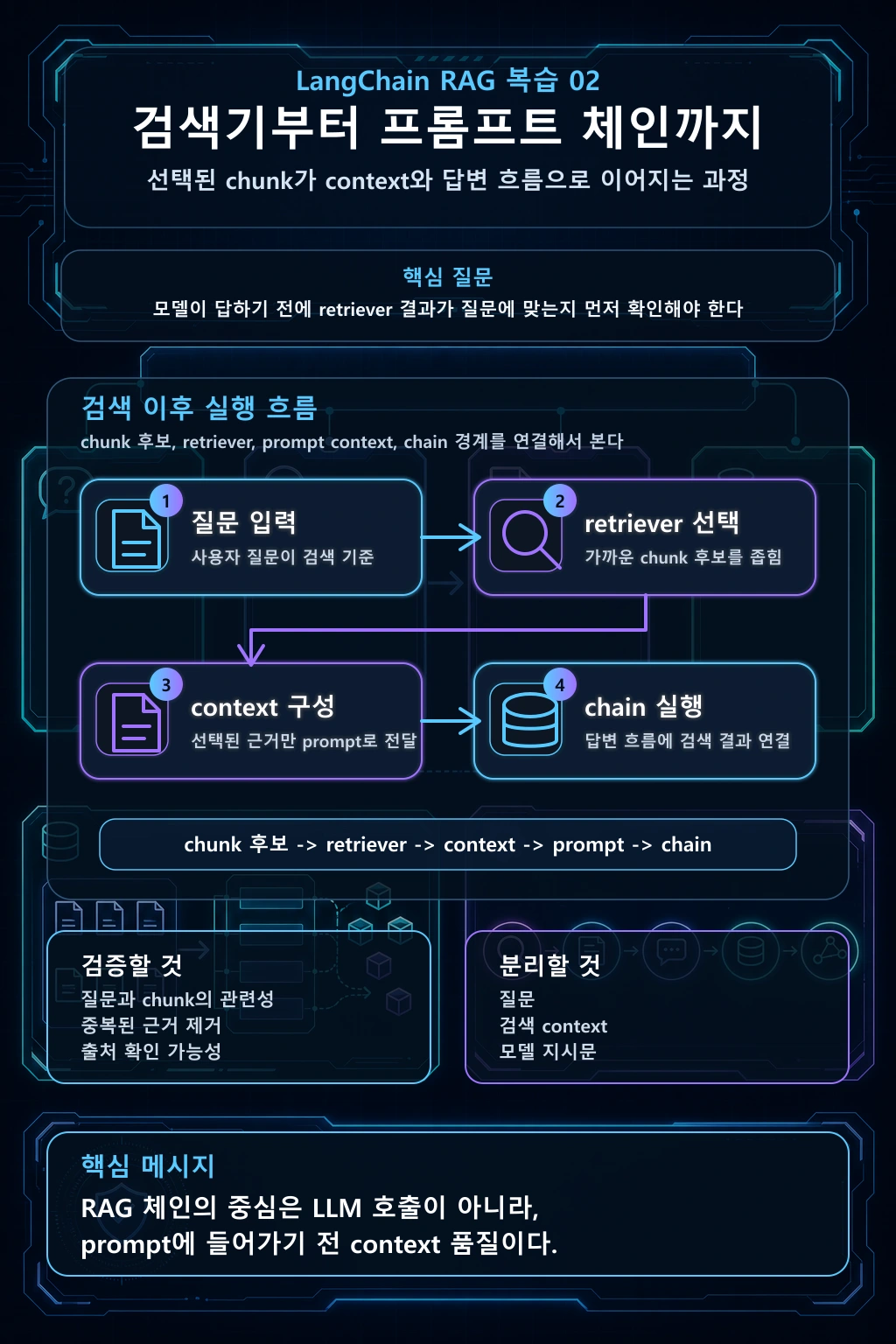
이 글의 흐름은 chunk에서 시작해 prompt 직전까지 간다. embedding model, vector store, retriever, prompt template, chain, query transformation을 따로따로 외우는 것이 아니라, 하나의 질문이 어떤 중간 산출물을 지나가는지 본다.
질문은 이렇게 둔다.
회의실 예약은 언제까지 가능한가?이 질문에 답하기 전에 먼저 확인할 것은 답변 문장이 아니다. retriever가 어떤 chunk를 가져왔는지, 그 chunk의 metadata가 살아 있는지, prompt에는 어떤 context가 들어가는지다.
embedding은 검색을 위한 표현 변환이다
chunk는 사람이 읽을 수 있는 텍스트다. 하지만 vector store에서 유사도를 비교하려면 chunk와 질문을 비교 가능한 표현으로 바꿔야 한다. 이때 embedding이 등장한다.
실제 서비스에서는 embedding provider나 vector database를 선택해야 하지만, 이 글에서는 provider 설정을 다루지 않는다. 대신 "텍스트가 비교 가능한 값으로 바뀌고, 그 값으로 chunk를 다시 찾는다"는 흐름만 본다.
아래 예시는 API 키 없이 구조를 보기 위한 단순 embedding이다. 실제 의미 임베딩은 아니지만, 질문이 들어가고 관련 chunk가 돌아오는 흐름을 눈으로 확인하기에는 충분하다.
from langchain_core.documents import Documentfrom langchain_core.embeddings import Embeddingsfrom langchain_community.vectorstores import FAISS class KeywordEmbeddings(Embeddings): terms = ["회의실", "예약", "장비", "보안"] def _embed(self, text: str) -> list[float]: return [float(text.count(term)) for term in self.terms] def embed_documents(self, texts: list[str]) -> list[list[float]]: return [self._embed(text) for text in texts] def embed_query(self, text: str) -> list[float]: return self._embed(text)여기서 봐야 할 것은 구현의 정교함이 아니다. chunk와 query가 같은 방식으로 표현되어야 검색이 가능하다는 점이다. 질문만 다른 방식으로 바꾸거나, 문서만 다른 기준으로 저장하면 retriever 결과를 믿기 어렵다.
vector store에는 텍스트와 metadata가 같이 들어간다
vector store는 벡터만 저장하는 곳처럼 보이지만, RAG 흐름에서는 chunk text와 metadata가 함께 살아 있어야 한다. 검색 결과로 벡터 점수만 돌아오면 prompt에 넣을 context도 없고, 출처도 설명할 수 없다.
chunks = [ Document( page_content="회의실 예약은 사용 시작 1시간 전까지 가능합니다.", metadata={ "source": "sample-office-guide.md", "section": "reservation", "version": "2026-06", }, ), Document( page_content="장비 대여는 안내 데스크에서 기록 후 반납합니다.", metadata={ "source": "sample-office-guide.md", "section": "equipment", "version": "2026-06", }, ), Document( page_content="보안 출입 카드는 승인된 대상만 신청할 수 있습니다.", metadata={ "source": "sample-office-guide.md", "section": "security", "version": "2026-06", }, ),] vector_store = FAISS.from_documents(chunks, KeywordEmbeddings())retriever = vector_store.as_retriever(search_kwargs={"k": 2})이 단계에서 k=2도 정답이 아니다. 한 질문에 몇 개의 chunk가 필요한지는 출력으로 판단해야 한다. 회의실 예약 질문에 예약 chunk 하나만 있으면 충분할 수도 있고, 사용 후 장비 확인 문장까지 필요할 수도 있다.
실행 예시: retriever 결과는 답변이 아니다
retriever를 실행하면 질문과 가까운 chunk가 돌아온다.
question = "회의실 예약은 언제까지 가능한가?"results = retriever.invoke(question) for doc in results: print(doc.page_content) print(doc.metadata)여기서 가장 중요한 문장은 "retriever 결과는 답변이 아니다"다. retriever는 답변 후보가 아니라 context 후보를 고른다. 회의실 예약 chunk가 첫 번째로 돌아오면 좋은 신호다. 하지만 두 번째 결과에 보안 출입 chunk가 섞여 있다면 prompt에 넣기 전에 한 번 더 판단해야 한다.
| 확인 지점 | 보는 내용 |
|---|---|
| 상위 결과 | 질문과 가까운 chunk가 먼저 왔는지 본다 |
| metadata | source, section, version이 같이 돌아왔는지 본다 |
| k 값 | context가 너무 적거나 많지 않은지 본다 |
| 반복 | 같은 내용이 중복해서 올라오지 않는지 본다 |
| 섞임 | 다른 주제의 chunk가 같이 들어오지 않았는지 본다 |
검색이 흔들리면 prompt를 잘 써도 답변은 흔들린다. 그래서 이 단계에서는 모델을 부르기 전에 결과 chunk를 먼저 읽는다.
prompt template은 입력 경계를 정한다
retriever 결과를 확인했다면 이제 prompt로 넘길 수 있다. 이때 prompt template은 단순한 문자열 포맷이 아니다. question, context, source가 각각 어디에 들어가는지 정하는 입력 경계다.
from langchain_core.prompts import ChatPromptTemplate prompt = ChatPromptTemplate.from_messages( [ ( "system", "너는 사내 지식 문서를 바탕으로만 답한다. context 밖의 내용을 지어내지 않는다.", ), ( "human", "질문: {question}\n\ncontext:\n{context}\n\nsource: {source}", ), ]) selected_docs = results[:1] payload = { "question": question, "context": "\n".join(doc.page_content for doc in selected_docs), "source": ", ".join( f"{doc.metadata['source']}#{doc.metadata['section']}@{doc.metadata['version']}" for doc in selected_docs ),} messages = prompt.format_messages(**payload) for message in messages: print(f"{message.type}: {message.content}")이 출력은 모델 호출 직전의 입력이다. 질문이 그대로 남았는지, context에는 retriever가 고른 chunk만 들어갔는지, source가 빠지지 않았는지 확인한다. 이 확인을 하지 않으면 답변이 이상할 때 retrieval 문제인지 prompt 문제인지 분리하기 어렵다.
chain은 마법이 아니라 handoff다
chain이라는 단어 때문에 모든 과정이 자동으로 이어지는 것처럼 보일 수 있다. 하지만 RAG에서 chain은 각 단계의 handoff가 보일 때 의미가 있다.
좋은 흐름은 이렇게 읽힌다.
question-> transformed query or original query-> retriever result-> prompt payload-> rendered prompt messages-> model answer-> answer with source각 단계에서 중간 값을 출력할 수 있어야 한다. 특히 retriever result와 rendered prompt는 꼭 봐야 한다. retriever 결과가 틀렸는데 prompt만 고치면 문제가 가려진다. prompt에 엉뚱한 context가 들어갔는데 모델만 바꾸면 같은 문제가 반복된다.
경계 사례: query transformation은 비교해야 한다
검색 품질을 높이기 위해 질문을 바꾸는 경우가 있다. 예를 들어 사용자의 자연어 질문을 검색에 더 잘 맞는 표현으로 바꾸는 것이다.
original_query = "회의실 예약은 언제까지 가능한가?"transformed_query = "예시 사내 지식 문서 회의실 예약 마감 시점" print("original:", original_query)print("transformed:", transformed_query)query transformation은 유용하지만 위험도 있다. 검색 힌트를 늘리다가 원래 질문의 의도가 바뀔 수 있기 때문이다. 언제까지 가능한가를 묻는 질문이 단순히 회의실 정책처럼 넓어지면 retriever는 더 많은 문서를 가져올 수 있지만 답변 중심은 흐려진다.
그래서 변환된 질문은 원 질문과 항상 나란히 봐야 한다. 검색에 쓰는 질문이 바뀌더라도 prompt에는 원래 사용자의 질문이 남아 있어야 한다. 검색을 위해 바꾼 표현이 답변의 의도까지 바꾸면 안 된다.
이 글에서 확인한 흐름
이번 글의 핵심은 답변 생성 이전의 경계다. chunk는 embedding을 거쳐 vector store에 들어간다. retriever는 질문과 가까운 chunk를 다시 꺼낸다. prompt template은 그 chunk를 context로 넣고, source 정보를 함께 넘긴다. chain은 이 handoff를 연결하지만, 중간 출력이 보이지 않으면 디버깅하기 어렵다.
이 흐름에서 확인할 것은 다음 다섯 가지다.
- 질문과 chunk가 같은 embedding 기준으로 비교되는가?
- vector store 결과에 chunk text와 metadata가 함께 남는가?
- retriever 결과가 답변 재료로 충분히 좁혀졌는가?
- prompt에는 의도한 context만 들어가는가?
- query transformation이 원래 질문의 의도를 유지하는가?
이 다섯 가지가 맞아야 모델 답변을 볼 준비가 된다. RAG에서 답변은 마지막에 나오는 문장이고, 품질은 그 전에 지나온 입력 경계에서 결정된다.
짧은 FAQ
Q. retriever 결과가 나오면 바로 LLM에 넣어도 되나?
A. 실행은 가능하지만 먼저 결과를 읽는 편이 낫다. 검색 결과가 틀렸는데 바로 LLM에 넣으면 모델은 틀린 context를 바탕으로 그럴듯한 답을 만들 수 있다.
Q. query transformation은 항상 써야 하나?
A. 아니다. 질문이 짧거나 문서 표현과 잘 맞으면 원 질문으로도 충분할 수 있다. 변환을 쓴다면 원 질문과 변환 질문을 함께 출력해서 의도가 유지되는지 확인해야 한다.
Q. source는 prompt에 꼭 넣어야 하나?
A. 출처 표시나 디버깅이 필요하다면 넣는 편이 좋다. 적어도 chain 내부의 payload에는 source를 유지해야 나중에 답변과 근거를 연결할 수 있다.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.