핵심 요약
- Claude Code 같은 제품형 AI coding agent는 단순한 모델 API wrapper가 아니다.
- 사용자의 입력은 곧바로 모델로 가지 않고, turn boundary와 input normalization을 통과한다.
- 모델 루프, tool runtime, permission gate, transcript ledger가 분리될 때 제품 수준 안정성이 나온다.
- AI를 쓰는 개발자는 이 구조를 알면 도구의 장단점을 더 정확히 판단할 수 있고, agent를 만드는 개발자는 최소 설계 경계를 잡을 수 있다.
이번 글에서는 Claude Code를 “코딩을 잘하는 AI 도구”가 아니라 제품 수준 AI agent runtime으로 읽어보겠습니다.
많은 개발자가 AI agent를 만들 때 처음 떠올리는 것은 모델 API 호출입니다. messages를 만들고, 모델에 보내고, 응답을 출력하면 agent가 되는 것처럼 보입니다. 데모에서는 어느 정도 맞습니다. 하지만 실제 개발자가 하루 종일 쓰는 도구가 되려면 이야기가 달라집니다.
Claude Code류의 CLI agent를 runtime 관점에서 보면 핵심은 모델 호출이 아닙니다. 사용자의 입력을 언제 하나의 턴으로 확정할지, 진행 중인 모델 스트림과 새 입력을 어떻게 조율할지, 모델이 요청한 도구를 어떤 권한으로 실행할지, 그리고 모든 사건을 어떻게 기록하고 복구할지가 더 중요합니다.
1. 왜 “Claude Code 분석”이라는 프레임이 유효한가
Claude Code는 개발자에게 매우 익숙한 표면을 가지고 있습니다. 터미널에서 질문하고, 코드베이스를 탐색하고, 파일을 수정하고, 테스트를 실행하도록 요청할 수 있습니다. 겉으로 보면 “터미널에 붙은 챗봇”처럼 보이지만, runtime 관점에서는 훨씬 복잡한 시스템입니다.
이 글에서 중요한 것은 특정 구현을 복제하는 것이 아닙니다. 오히려 반대입니다. 원본 코드를 직접 보여주지 않고도 제품 수준 agent가 어떤 경계를 가져야 하는지 설명하는 것이 목적입니다.
이 프레임이 좋은 이유는 독자가 바로 실무 질문으로 연결할 수 있기 때문입니다.
| 독자 | 이 글을 읽고 얻어야 하는 것 |
|---|---|
| AI 도구를 쓰는 개발자 | 내가 쓰는 agent가 왜 가끔 멈추고, 왜 승인창을 띄우고, 왜 비용이 늘어나는지 이해한다 |
| AI agent를 만드는 개발자 | 모델 호출 이전과 이후에 필요한 runtime 경계를 파악한다 |
| 팀 리드/플랫폼 엔지니어 | 팀에 도입할 때 권한, 기록, 비용, 보안 기준을 세운다 |
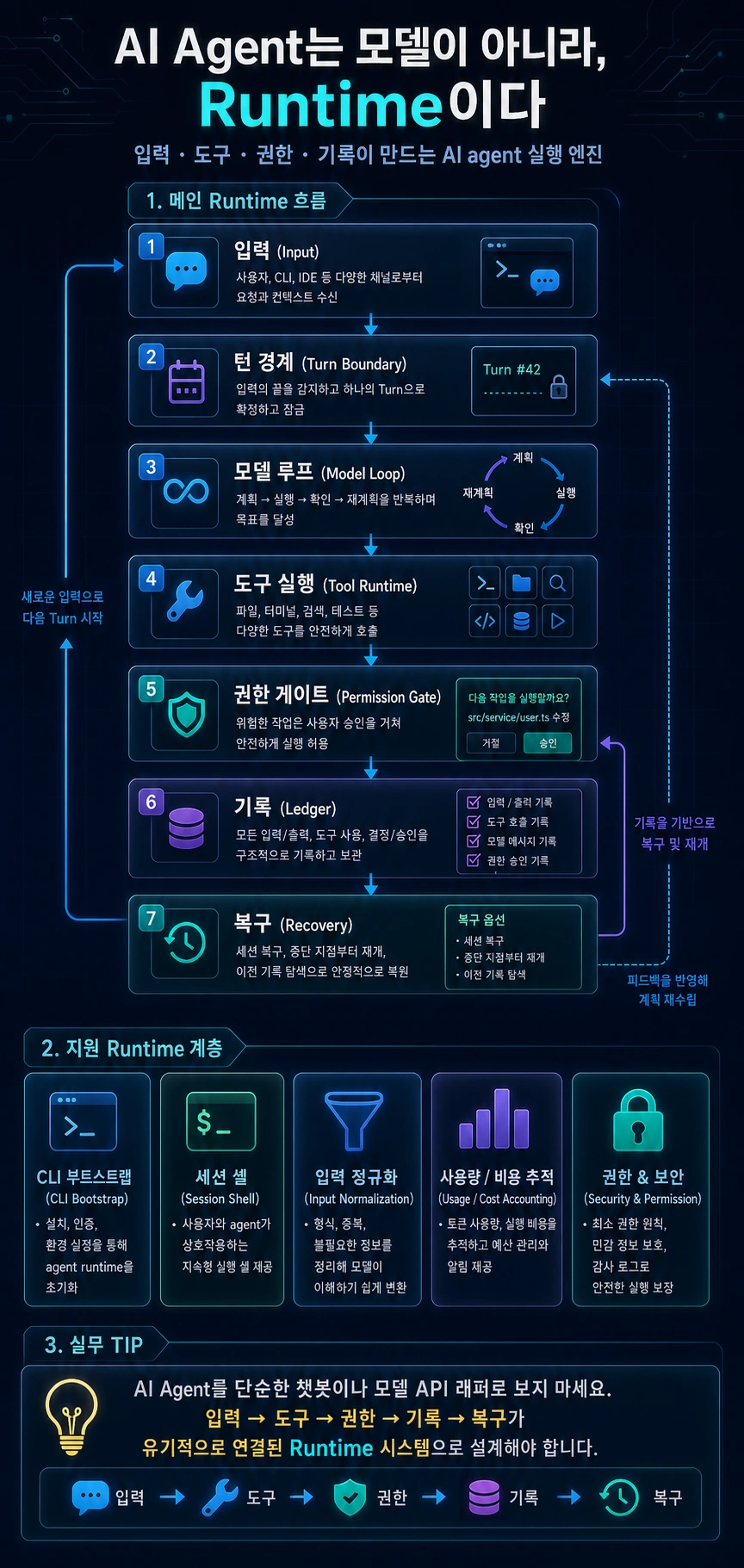
2. Agent runtime을 이루는 7개 계층
제품형 agent를 구성하는 계층은 크게 일곱 개로 나눌 수 있습니다.
| 계층 | 책임 | 무너지면 생기는 문제 |
|---|---|---|
| CLI bootstrap | 설정, 인증, 정책, 실행 모드 결정 | 시작부터 잘못된 권한과 환경으로 실행됨 |
| Session shell | 화면 상태, 입력창, 메시지, 승인 대기열 | UI와 모델 상태가 섞여 복구가 어려움 |
| Submit boundary | 입력을 즉시 실행/큐잉/명령으로 분기 | 두 턴이 동시에 같은 상태를 수정함 |
| Input normalization | raw input을 model-visible message로 변환 | 모델에게 보여주면 안 되는 정보가 섞임 |
| Model loop | 스트리밍 응답과 tool request 반복 | 도구 결과 이후 추론이 이어지지 않음 |
| Tool runtime | 도구 검색, 검증, 권한, 실행 | 모델이 낸 잘못된 요청이 그대로 실행됨 |
| Ledger/accounting | transcript, usage, cost, restore | 왜 실행됐는지, 얼마 썼는지 설명 불가 |
여기서 핵심은 계층이 많다는 사실이 아닙니다. 각 계층이 서로 다른 실패 모드를 막는다는 점입니다. 입력 계층의 실패는 중복 실행으로 이어지고, 도구 계층의 실패는 위험한 side effect로 이어지며, 기록 계층의 실패는 감사와 복구 불가능성으로 이어집니다.
3. AI를 쓰는 개발자가 봐야 할 지점
AI coding agent를 사용하는 개발자는 보통 결과물만 봅니다. 코드가 잘 수정됐는지, 테스트가 통과했는지, 답변이 빠른지에 집중합니다. 그런데 실제 업무에서는 다음 질문이 더 중요해집니다.
- 이 도구가 파일을 수정하기 전에 나에게 묻는가?
- 어떤 명령을 실행했는지 기록으로 남는가?
- 실패했을 때 이전 상태로 돌아갈 수 있는가?
- 긴 작업 중간에 비용과 토큰 사용량을 알 수 있는가?
- 대화 중 새 입력을 넣었을 때 이전 작업과 충돌하지 않는가?
Claude Code를 runtime 관점으로 읽으면 이런 질문들이 “사용성”이 아니라 “아키텍처”의 문제라는 점이 보입니다. 좋은 agent는 모델이 똑똑해서만 좋은 것이 아니라, 모델이 위험한 요청을 했을 때 runtime이 그 요청을 다루는 방식이 좋습니다.
4. Agent를 만드는 개발자가 봐야 할 지점
agent를 직접 만든다면 모델 provider wrapper부터 만들고 싶어집니다. 하지만 제품으로 확장하려면 순서가 달라져야 합니다.
먼저 정의해야 하는 것은 turn입니다. 사용자의 입력이 언제 시작되고 언제 끝나는지, 어떤 도구 요청과 결과가 그 턴에 속하는지, 중단되면 어떤 상태로 기록되는지가 정해져야 합니다.
그다음은 message projection입니다. 화면에 보이는 메시지, 모델에게 보내는 메시지, transcript에 남기는 메시지는 서로 다릅니다. 이 세 가지를 처음부터 분리하지 않으면 나중에 권한 UI, 비용 표시, 재개 기능을 붙일 때 계속 꼬입니다.
마지막으로 capability execution입니다. 모델이 도구를 호출한다고 해서 바로 실행해서는 안 됩니다. 이름이 맞는지, 인자가 맞는지, 실행 가능한 권한인지, 병렬로 실행해도 되는지를 runtime이 판단해야 합니다.
5. 추상화된 실행 흐름
아래 코드는 원본 구현이 아닙니다. 제품형 AI agent의 구조를 이해하기 위해 새로 작성한 개념 코드입니다.
# 읽는 법: 실제 구현 복제가 아니라 runtime 경계를 설명하는 개념 코드입니다.class AgentRuntime: # 객체가 이후 단계에서 참조할 runtime 의존성과 상태 저장소를 초기화합니다. def __init__(self, shell, model, capabilities, policy, ledger): self.shell = shell self.model = model self.capabilities = capabilities self.policy = policy self.ledger = ledger self.active_turn = None self.waiting_inputs = [] # 사용자 입력 하나를 turn으로 확정하고 local 처리, queue, model loop 중 하나로 보냅니다.async def handle_prompt(runtime: AgentRuntime, raw_prompt: str): draft = create_turn_draft(raw_prompt, runtime.shell.snapshot()) if runtime.active_turn is not None: runtime.waiting_inputs.append(draft) runtime.shell.notice("현재 작업이 끝난 뒤 이어서 처리합니다.") return prepared = await normalize_turn_input(draft, runtime) if prepared.local_only: await run_local_effect(prepared, runtime) return runtime.active_turn = prepared.turn_id try: await drive_agent_until_done(prepared.messages, runtime) finally: await runtime.ledger.flush_turn(prepared.turn_id) runtime.active_turn = None이 코드에서 핵심은 handle_prompt()가 모델을 직접 호출하지 않는다는 점입니다. 입력은 먼저 draft가 되고, draft는 normalize되고, 그 결과가 local action인지 model query인지 분기됩니다. 진행 중인 턴이 있으면 새 입력은 queue에 들어갑니다.
6. 제품 수준 agent의 설계 패턴
첫 번째 패턴은 turn boundary를 UI event handler에서 분리하는 것입니다. Enter 키를 누른 순간 바로 모델을 호출하면 취소, 큐잉, 재시도, 원격 입력, 승인 대기열을 처리하기 어렵습니다.
두 번째 패턴은 model loop와 tool runtime을 분리하는 것입니다. 모델은 도구 사용을 요청할 뿐입니다. 실제 실행 여부는 runtime이 판단해야 합니다. 이 경계가 있어야 permission, sandbox, schema validation, progress event를 독립적으로 개선할 수 있습니다.
세 번째 패턴은 ledger를 로그가 아니라 기능으로 보는 것입니다. agent는 비결정적이고 장기 실행됩니다. transcript와 usage 기록이 없으면 사용자가 무엇을 승인했는지, 어떤 도구 결과를 보고 다음 판단이 나왔는지 알 수 없습니다.
실무 팁
agent를 처음 만들 때는 모델 wrapper보다Turn,RuntimeEvent,CapabilityResult,LedgerEvent타입을 먼저 설계해보세요. 이 네 가지가 잡히면 provider를 바꾸거나 도구를 추가해도 구조가 덜 흔들립니다.
7. 내 agent에 적용하는 방법
작게 시작한다면 다음 다섯 개 타입만으로도 충분합니다.
| 타입 | 담아야 할 정보 |
|---|---|
TurnDraft | 원본 입력, 첨부, 입력 출처, 실행 모드 |
PreparedTurn | 모델에게 보낼 메시지, local 처리 여부, 허용 도구 |
RuntimeEvent | assistant text, tool request, usage update, final state |
CapabilityResult | 도구 요청 ID, 성공/실패, 요약, model-visible content |
LedgerEvent | 시간, turn id, visible scope, model scope, 비용 정보 |
이렇게 두면 agent가 커져도 각 기능을 어디에 붙여야 하는지 명확해집니다. 예를 들어 새 slash command는 input normalization 또는 command dispatch 계층에 들어가고, 새 도구는 capability runtime에 들어가며, 비용 표시는 ledger/accounting 계층에 들어갑니다.
8. 실전 체크리스트
# 읽는 법: 아래 항목은 동작 흐름을 빠르게 확인하기 위한 요약 예시입니다.Agent runtime 점검 체크리스트 [ ] 입력 제출과 모델 호출이 분리되어 있다.[ ] 진행 중인 turn이 있을 때 새 입력을 어떻게 처리할지 정해져 있다.[ ] 화면에 보이는 메시지와 모델에게 보내는 메시지가 분리되어 있다.[ ] 모델이 요청한 도구는 실행 전에 schema validation을 통과한다.[ ] 위험한 도구는 permission gate를 통과해야 한다.[ ] 도구 실패도 model-visible result로 재주입된다.[ ] transcript는 사용자 입력, 도구 요청, 권한 결정, 비용을 함께 남긴다.[ ] 중단 신호는 모델 스트림과 도구 실행 양쪽에 전달된다.마무리
Claude Code를 runtime 관점으로 읽으면 AI agent를 보는 기준이 바뀝니다. 더 이상 “어떤 모델을 쓰는가”만 보지 않게 됩니다. 대신 입력이 어떻게 턴이 되는지, 도구가 어떤 권한으로 실행되는지, 실패와 중단이 어떻게 기록되는지를 보게 됩니다.
다음 글에서는 이 runtime이 프로세스 시작 시점에 무엇을 먼저 정리하는지 보겠습니다. Agent CLI의 bootstrap은 단순 argument parsing이 아니라, 실행 전 신뢰 경계를 만드는 단계입니다.
Key takeaways
- A product-type AI coding agent like Claude Code is not a simple model API wrapper.
- The user's input does not go directly to the model, but passes through a turn boundary and input normalization.
- Product-level stability occurs when the model loop, tool runtime, permission gate, and transcript ledger are separated.
- By knowing this structure, developers who use AI can more accurately judge the pros and cons of the tool, and developers who create agents can set the minimum design boundary.
In this article, we will read Claude Code not as an “AI tool that is good at coding,” but as a product-level AI agent runtime.
The first thing that many developers think of when creating an AI agent is a model API call. If you createmessages, send it to the model, and print the response, it appears to be an agent. In the demo, this is somewhat correct. But for it to become a tool that real developers use all day, it's a different story.
If you look at Claude Code-type CLI agents from a runtime perspective, the key is not the model call. More important are when to confirm user input into a turn, how to coordinate new input with ongoing model streams, with what permissions to run tools requested by the model, and how to record and recover all events.
1. Why is the frame “Claude Code Analysis” effective?
Claude Code has a very familiar surface to developers. From the terminal, you can ask questions, explore the codebase, modify files, and ask to run tests. On the outside, it looks like a “chatbot attached to a terminal,” but it is a much more complex system from a runtime perspective.
The point of this article is not to replicate a specific implementation. Quite the opposite. The goal is to explain what boundaries a product-level agent should have without directly showing the original code.
What makes this frame great is that it takes the reader straight to action questions.
| reader | What you should get from reading this article |
|---|---|
| Developer using AI tools | I understand why the agent I use sometimes stops, why an approval window appears, and why costs increase. |
| Developer who creates AI agent | Identify the necessary runtime boundaries before and after model calls. |
| Team Lead/Platform Engineer | Establish standards for permissions, records, costs, and security when introducing it to your team. |
2. 7 layers that make up agent runtime
The layers that make up a product-type agent can be broadly divided into seven.
| hierarchy | responsibility | Problems that arise when it collapses |
|---|---|---|
| CLI bootstrap | Determine settings, authentication, policies, and execution modes | Runs with incorrect permissions and environment from the start |
| Session shell | Screen status, input window, message, approval queue | Difficult to recover because UI and model state are mixed |
| Submit boundary | Immediately execute/queue/branch input to command | Two turns modify the same state at the same time |
| Input normalization | Convert raw input to model-visible message | Information that should not be shown to the model is mixed in. |
| Model loop | Streaming response and tool request repetition | Inference does not follow the tool results |
| tool runtime | Tool discovery, verification, permissions, execution | Invalid requests made by the model are executed as is. |
| Ledger/accounting | transcript, usage, cost, restore | Can't explain why it was implemented or how much was spent |
The point here is not that there are many layers. Each layer prevents different failure modes. Failure of the input layer leads to redundant execution, failure of the tools layer leads to dangerous side effects, and failure of the history layer leads to auditability and unrecoverability.
3. Points that developers using AI should look at
Developers who use AI coding agents usually only see the results. Focus on whether the code was well modified, whether the tests passed, and whether the response was quick. However, in actual work, the following questions become more important.
- Does this tool ask me before modifying the file?
- Is there a record of what commands were executed?
- In case of failure, is it possible to return to the previous state?
- Can I know the cost and token usage in the middle of a long task?
- When I enter new input during a conversation, doesn't it conflict with previous operations?
If you read Claude Code from a runtime perspective, you will see that these questions are not “usability” issues but “architecture” issues. A good agent is not only good because the model is smart, but also the way the runtime handles the request when the model makes a risky request.
4. Points that developers creating Agents should look at
If you create the agent yourself, you will want to create a model provider wrapper first. But scaling to a product requires a different order.
The first thing we need to define isturn. It must be determined when user input begins and ends, which tool requests and results belong to that turn, and what state is recorded when interrupted.
Next ismessage projection. The message displayed on the screen, the message sent to the model, and the message left in the transcript are different. If you don't separate these three from the beginning, things will get messy later when you add permission UI, cost display, and resume functionality.
Lastly iscapability execution. Just because your model calls a tool doesn't mean you should run it right away. The runtime must determine whether the name is correct, the arguments are correct, whether the permissions are executable, and whether it can be executed in parallel.
5. Abstracted execution flow
The code below is not the original implementation. This is a newly written concept code to understand the structure of a product-type AI agent.
# How to read: Conceptual code that describes runtime boundaries, not a clone of the actual implementation.class AgentRuntime: # Initializes runtime dependencies and state storage that the object will reference in later steps. def __init__(self, shell, model, capabilities, policy, ledger): self.shell = shell self.model = model self.capabilities = capabilities self.policy = policy self.ledger = ledger self.active_turn = None self.waiting_inputs = [] # Confirms one user input as a turn and sends it to one of local processing, queue, or model loop.async def handle_prompt(runtime: AgentRuntime, raw_prompt: str): draft = create_turn_draft(raw_prompt, runtime.shell.snapshot()) if runtime.active_turn is not None: runtime.waiting_inputs.append(draft) runtime.shell.notice("Processing continues after the current task is finished.") return prepared = await normalize_turn_input(draft, runtime) if prepared.local_only: await run_local_effect(prepared, runtime) return runtime.active_turn = prepared.turn_id try: await drive_agent_until_done(prepared.messages, runtime) finally: await runtime.ledger.flush_turn(prepared.turn_id) runtime.active_turn = NoneThe key point in this code is thathandle_prompt()does not call the model directly. The input is first a draft, the draft is normalized, and the result is branched into whether it is a local action or a model query. If there is a turn in progress, new input is put into the queue.
6. Design patterns for product-level agents
The first pattern is to separate the turn boundary from the UI event handler. Invoking a model immediately after pressing Enter makes it difficult to handle cancellation, queuing, retries, remote input, and acknowledgment queues.
The second pattern is to separate the model loop and tool runtime. The model simply asks you to use the tool. Runtime must determine whether it is actually executed. This boundary allows permission, sandbox, schema validation, and progress events to be improved independently.
The third pattern is to view the ledger as a function rather than a log. The agent is non-deterministic and long-running. Without transcript and usage records, it is impossible to know what the user approved or what tool results led to the next decision.
Practical Tips When first creating an agent, design the
Turn,RuntimeEvent,CapabilityResult, andLedgerEventtypes first rather than the model wrapper. If these four things are caught, the structure will be less shaken even if you change the provider or add tools.
7. How to apply it to my agent
If you're starting small, the following five types will suffice.
| type | Information to include |
|---|---|
TurnDraft | Original input, attachment, input source, execution mode |
PreparedTurn | Message to be sent to model, local processing, permission tools |
RuntimeEvent | assistant text, tool request, usage update, final state |
CapabilityResult | Tool request ID, success/failure, summary, model-visible content |
LedgerEvent | Time, turn id, visible scope, model scope, cost information |
If you do this, even if the agent grows, it will be clear where each function should be attached. For example, a new slash command goes into the input normalization or command dispatch layer, a new tool goes into the capability runtime, and a cost display goes into the ledger/accounting layer.
8. Practical checklist
# How to read: The items below are summarized examples to quickly check the action flow.agent runtime inspection checklist [ ] Input submission and model call are separated.[ ] It is determined how to handle new input when there is a turn in progress.[ ] The message displayed on the screen and the message sent to the model are separated.[ ] The tool requested by the model passes schema validation before execution.[ ] Dangerous tools must pass the permission gate.[ ] Tool failures are also reinjected as model-visible results.[ ] The transcript records user input, tool requests, permission decisions, and costs.[ ] Abort signals are sent to both the model stream and the tool execution.finish
If you read Claude Code from a runtime perspective, your standard for viewing AI agents changes. You are no longer just looking at “what model are you using?” Instead, you see how input is rotated, what permissions the tool runs with, and how failures and hangs are logged.
In the next article, we'll see what this runtime cleans up first at the start of the process. Agent CLI's bootstrap is not simple argument parsing, but is a step in creating a trust boundary before execution.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.