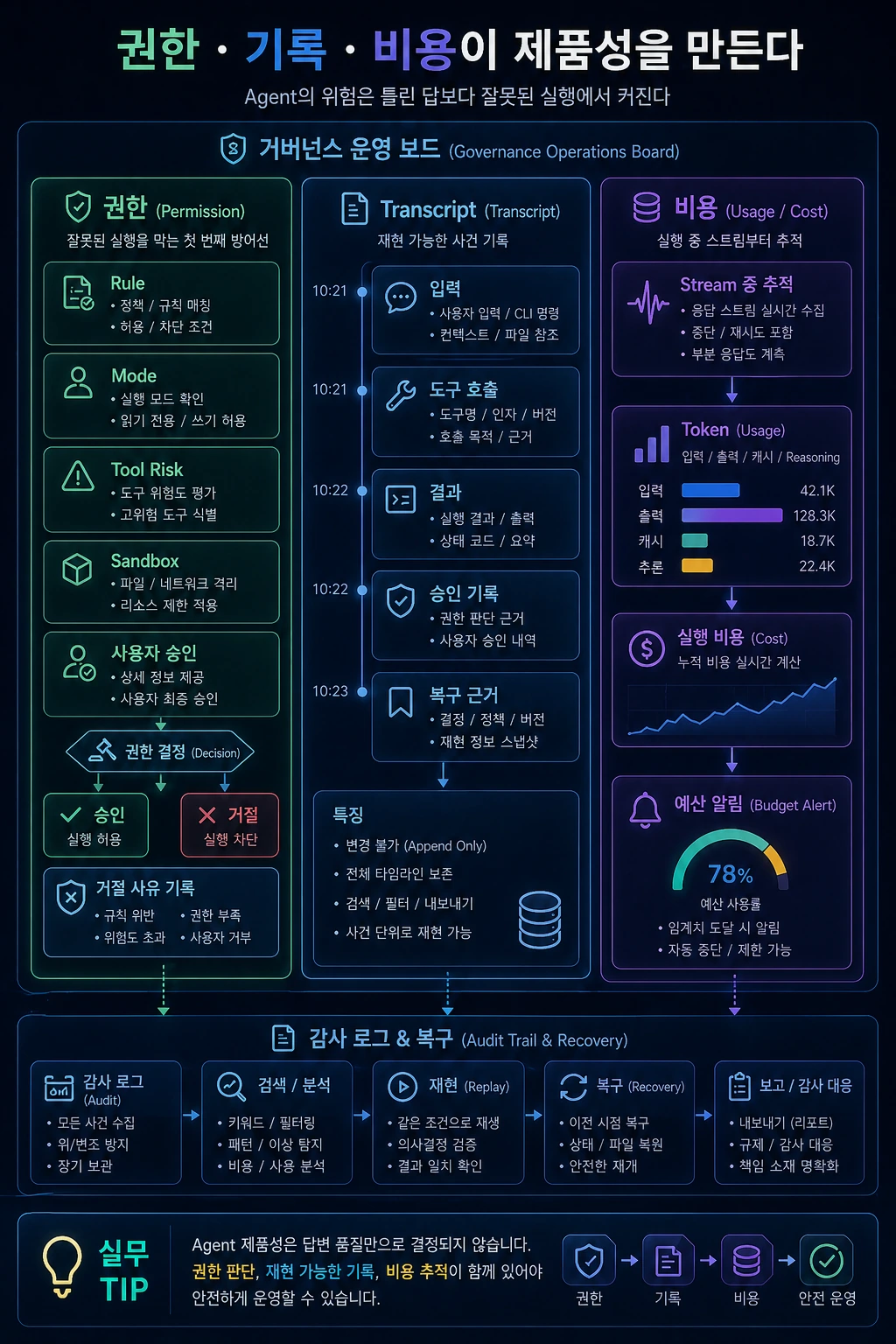
핵심 요약
- Agent의 위험은 틀린 답보다 잘못된 실행에서 커진다.
- Permission gate는 단일 if 문이 아니라 rule, mode, tool risk, sandbox, user approval을 보는 계층이다.
- Transcript는 채팅 로그가 아니라 재현 가능한 사건 기록이다.
- Usage와 cost는 장기 실행 agent에서 stream 중간부터 추적되어야 한다.
마지막 글에서는 agent 제품성의 마지막 방어선을 다룹니다. 권한, transcript, 비용입니다.
AI agent의 위험은 모델이 틀린 답을 하는 데서만 오지 않습니다. 더 큰 위험은 모델이 사용자의 파일을 바꾸거나, shell 명령을 실행하거나, 외부 시스템에 데이터를 보낼 때 발생합니다. 그래서 permission, transcript, cost accounting은 나중에 붙이는 부가기능이 아니라 runtime의 핵심입니다.
Claude Code류의 agent를 분석 관점으로 보면 이 셋은 같은 사건을 서로 다른 방식으로 봅니다. 도구 요청이 들어오면 permission gate가 판단하고, ledger는 그 결정을 기록하고, accounting은 모델과 도구 사용량을 추적합니다.
1. 권한은 왜 마지막 방어선인가
모델은 의도를 추론하지만, 실행의 책임은 runtime에 있습니다. 모델이 “이 파일을 수정하자”고 말할 수는 있지만, 실제 파일 쓰기를 허용할지는 runtime이 결정해야 합니다.
권한 설계가 약하면 다음 문제가 생깁니다.
- 사용자가 승인하지 않은 파일 수정
- 위험한 shell 명령 실행
- 비밀키나 환경변수 노출
- 외부 네트워크로 민감 데이터 전송
- 어떤 작업이 왜 실행됐는지 설명 불가
보안 주의:
AI agent를 회사 코드베이스에 적용하기 전에는 권한 모드, 로그 보관 범위, 데이터 전송 범위, 비밀 정보 마스킹, rollback 절차를 반드시 확인해야 합니다.
2. Layered permission 설계
좋은 permission gate는 단일 boolean check가 아닙니다. 여러 계층을 순서대로 봅니다.
| 순서 | 계층 | 설명 |
|---|---|---|
| 1 | explicit deny | 명시적으로 금지된 작업 차단 |
| 2 | policy rule | 조직/프로젝트/사용자 규칙 적용 |
| 3 | tool risk | 도구의 위험도 확인 |
| 4 | argument risk | 입력값 자체의 위험 판단 |
| 5 | sandbox mode | 격리 실행 가능 여부 확인 |
| 6 | auto-allow | 안전 조건에서만 자동 허용 |
| 7 | interactive approval | 사용자에게 질문 |
| 8 | decision record | 결정과 이유 기록 |
중요한 것은 자동 허용이 안전 검사보다 뒤에 와야 한다는 점입니다. 자동화는 편의 기능이지 안전장치 해제가 아닙니다.
3. 승인 UI와 결정 기록
사용자에게 묻는 것은 permission gate의 일부지만, UI와 정책 판단은 분리해야 합니다.
정책 엔진은 다음 중 하나를 반환합니다.
- 허용
- 거부
- 사용자 확인 필요
UI는 “사용자 확인 필요”를 사람이 이해할 수 있는 dialog로 바꿉니다. 그리고 사용자의 선택은 ledger에 남아야 합니다.
| 기록 항목 | 이유 |
|---|---|
| capability name | 어떤 도구인지 식별 |
| argument summary | 무엇을 하려 했는지 설명 |
| decision | 허용/거부/항상 허용 |
| reason | 정책, 사용자 선택, 위험도 |
| approver | 사람이 승인했는지 자동 승인인지 |
| turn id | 어떤 agent turn에 속하는지 연결 |
4. Transcript를 채팅 로그로 보면 안 되는 이유
transcript는 “대화 내용 저장”이 아닙니다. agent 실행을 재현하기 위한 사건 기록입니다.
좋은 transcript는 다음 질문에 답할 수 있어야 합니다.
- 사용자가 어떤 입력을 보냈는가?
- 모델은 어떤 도구를 요청했는가?
- runtime은 어떤 권한 결정을 내렸는가?
- 사용자는 무엇을 승인했는가?
- 도구 결과는 무엇이었는가?
- 그 결과를 보고 모델은 어떤 다음 판단을 했는가?
- 비용과 토큰은 어느 시점에 증가했는가?
이 질문에 답하지 못하면 디버깅, 감사, 복구가 어렵습니다.
5. Usage와 cost accounting
장기 실행 agent는 여러 번 모델을 호출하고, 도구 결과를 다시 넣고, context를 압축하고, retry를 수행할 수 있습니다. 비용을 마지막에 한 번 계산하면 오차가 커집니다.
따라서 usage와 cost는 stream event 단계에서 누적해야 합니다.
| 이벤트 | accounting 처리 |
|---|---|
| model request start | 요청 metadata 기록 |
| usage update | token/cache/reasoning 사용량 병합 |
| tool execution | tool call count, 외부 API 비용 기록 |
| retry/fallback | 별도 request로 연결 |
| cancel | 현재까지 사용량 확정 |
| final | turn summary 생성 |
6. 개념 코드로 보는 안전 계층
아래 코드는 설명용으로 새로 작성한 코드입니다.
# 읽는 법: 실제 구현 복제가 아니라 runtime 경계를 설명하는 개념 코드입니다.class PermissionDecision: # 객체가 이후 단계에서 참조할 runtime 의존성과 상태 저장소를 초기화합니다. def __init__(self, allowed, reason, requires_user=False): self.allowed = allowed self.reason = reason self.requires_user = requires_user # 정책, 위험도, 자동 허용 조건, 사용자 승인 순서로 실행 가능 여부를 결정합니다.async def evaluate_permission(tool, args, runtime): if runtime.policy.denies(tool, args): return PermissionDecision(False, "explicit_deny") risk = classify_risk(tool, args, runtime.workspace) if risk.level == "blocked": return PermissionDecision(False, risk.reason) if runtime.policy.auto_allows(tool, args, risk): return PermissionDecision(True, "auto_allow") user_choice = await runtime.shell.ask_approval( title=f"{tool.name} 실행 승인", body=build_risk_explanation(tool, args, risk), ) if user_choice == "deny": return PermissionDecision(False, "user_denied") return PermissionDecision(True, f"user_{user_choice}") # 권한 결정을 ledger에 남긴 뒤 허용된 도구만 실제 실행합니다.async def guarded_tool_execution(request, runtime): decision = await evaluate_permission(request.tool, request.args, runtime) await runtime.ledger.write("permission", { "tool": request.tool.name, "decision": decision.allowed, "reason": decision.reason, "turn": runtime.current_turn_id, }) if not decision.allowed: return ToolResult.denied(request.id, decision.reason) result = await runtime.tools.execute_without_rechecking(request) await runtime.ledger.write("tool_result", result.audit_summary()) return result권한 판단과 기록은 분리되어 있지만 같은 사건을 공유합니다. 이렇게 해야 나중에 “왜 실행됐는가”를 설명할 수 있습니다.
7. AI 활용 개발자 관점
AI 도구를 쓰는 개발자는 다음을 확인해야 합니다.
| 질문 | 이유 |
|---|---|
| 파일 쓰기 전에 승인을 요구하는가? | 원치 않는 변경 방지 |
| shell 명령을 보여주고 실행하는가? | 위험 명령 확인 |
| 항상 허용 규칙을 관리할 수 있는가? | 과도한 자동화 방지 |
| transcript를 확인할 수 있는가? | 감사와 디버깅 |
| 비용/토큰 사용량을 볼 수 있는가? | 예산 관리 |
| 실패 후 rollback이 쉬운가? | 실무 안정성 |
팀에서 도입한다면 이 질문들이 곧 도입 기준이 됩니다.
8. Agent 개발자 체크리스트
# 읽는 법: 아래 항목은 동작 흐름을 빠르게 확인하기 위한 요약 예시입니다.Permission / Transcript / Cost 체크리스트 [ ] 권한 판단은 단일 if가 아니라 layered gate로 설계되어 있다.[ ] explicit deny와 민감 작업 검사는 auto-allow보다 먼저 실행된다.[ ] 승인 UI와 정책 엔진이 분리되어 있다.[ ] 권한 거절도 model-visible tool result로 돌아간다.[ ] transcript는 사용자 입력, 모델 응답, tool request, permission decision, result를 연결한다.[ ] usage/cost는 stream 중간에도 갱신된다.[ ] cancel/retry/fallback 상황에서도 accounting이 유지된다.[ ] session restore 시 transcript와 cost state가 함께 복원된다.9. 운영 예시: 승인과 비용을 같은 run ledger에 묶기
긴 agent 작업에서는 권한 결정과 비용 기록을 따로 보면 원인을 놓치기 쉽습니다. 예를 들어 agent가 파일 3개를 수정하고 테스트를 4번 실행한 뒤 provider fallback까지 썼다면, 최종 답변만으로는 왜 비용이 늘었는지 알 수 없습니다. run ledger에는 permission decision, tool call, transcript checkpoint, usage snapshot이 같은 trace id로 묶여야 합니다.
| 기록 | 나중에 확인할 질문 |
|---|---|
| permission decision | 사용자가 어떤 쓰기 작업을 승인했는가 |
| transcript checkpoint | 모델이 어떤 관찰값을 보고 다음 판단을 했는가 |
| usage snapshot | 어느 turn에서 비용이 커졌는가 |
| cost limit event | 예산 초과 전에 중단했는가 |
실패 사례는 비용 추적을 billing dashboard에만 맡기는 구조입니다. 월말 총액은 알 수 있지만 어떤 작업, 어떤 prompt version, 어떤 tool retry가 비용을 만든 것인지 찾기 어렵습니다. 반대로 run ledger에 토큰 원문이나 민감한 prompt 전문을 모두 저장하면 보안 문제가 생깁니다. 저장해야 하는 것은 원문 전체가 아니라 model, prompt version, input/output token, cached token, tool retry count처럼 판단 가능한 요약값입니다.
10. 마무리 Q&A
Q1. 권한을 너무 자주 물으면 사용성이 나빠지지 않나?
맞습니다. 그래서 layered permission이 필요합니다. 안전한 read-only 작업은 자동 허용할 수 있고, 위험한 write/shell/network 작업은 승인하도록 나눠야 합니다.
Q2. transcript는 모든 내용을 그대로 저장해야 하나?
아닙니다. 민감 정보는 마스킹하거나 요약해야 합니다. 중요한 것은 원본을 무조건 저장하는 것이 아니라 사건 순서와 결정 이유를 복구 가능하게 남기는 것입니다.
Q3. 비용 추적은 MVP에서 빼도 되나?
개인 데모라면 가능하지만, 장기 실행 agent나 팀 도입을 생각한다면 초기에 최소한의 usage snapshot은 넣는 편이 좋습니다. 나중에 붙이면 request, retry, cancellation의 연결을 복원하기 어렵습니다.
최종 정리
Claude Code류의 agent를 runtime 관점으로 분석하면 마지막에 남는 질문은 하나입니다.
이 agent는 자동화할 수 있는가보다, 안전하게 자동화할 수 있는가?
권한, transcript, 비용은 이 질문에 답하기 위한 핵심 계층입니다. 이 셋이 없으면 agent는 빠를 수는 있지만 신뢰하기 어렵습니다. 반대로 이 셋을 처음부터 설계하면 작은 agent도 제품 수준으로 성장할 수 있습니다.
Key takeaways
- The agent's risk is greater from a wrong execution than from a wrong answer.
- Permission gate is not a single if statement, but a layer that looks at rule, mode, tool risk, sandbox, and user approval.
- Transcript is not a chat log, but a reproducible record of events.
- Usage and cost should be tracked from mid-stream in long-running agents.
The final article addresses the last line of defense of agent productivity. Permission, transcript, cost.
The risk of AI agents does not come only from the model giving wrong answers. A greater risk occurs when the model replaces the user's files, executes shell commands, or sends data to external systems. So permission, transcript, and cost accounting are not add-on functions added later, but are the core of the runtime.
If we look at Claude Code-type agents from an analytical perspective, these three view the same event in different ways. When a tool request comes in, the permission gate makes a decision, the ledger records the decision, and accounting tracks model and tool usage.
1. Why authority is the last line of defense
The model infers the intent, but the responsibility for execution lies with the runtime. The model can say “let’s edit this file,” but the runtime must decide whether to actually allow writing to the file.
Weak permission design leads to the following problems:
- Modifying files without user permission
- Executing dangerous shell commands
- Exposure of secret keys or environment variables
- Sensitive data transfer to external networks
- Unable to explain why something was done
Security Note: Before applying an AI agent to a company's codebase, you must check the permission mode, log storage scope, data transmission scope, confidential information masking, and rollback procedures.
2. Layered permission design
A good permission gate is not a single boolean check. View multiple layers in order.
| order | hierarchy | explanation |
|---|---|---|
| 1 | explicit deny | Block explicitly prohibited actions |
| 2 | policy rule | Apply organization/project/user rules |
| 3 | tool risk | Check the risk of the tool |
| 4 | argument risk | Determination of risk of input value itself |
| 5 | sandbox mode | Check if quarantine is feasible |
| 6 | auto-allow | Automatically allowed only under safe conditions |
| 7 | interactive approval | Ask the user |
| 8 | decision record | Record decisions and reasons |
The important thing is that auto-acceptance must come after safety checks. Automation is a convenience feature, not a safety feature.
3. Approval UI and decision record
Prompting the user is part of a permission gate, but UI and policy decisions must be separated.
The policy engine returns one of the following:
- allowance
- refusal
- User confirmation required
The UI turns “user confirmation required” into a human-understandable dialog. And the user's choice should remain in the ledger.
| record entry | reason |
|---|---|
| capability name | Identify which tool it is |
| argument summary | explain what you were trying to do |
| decision | Allow/Deny/Always Allow |
| reason | Policies, user choices, risk |
| approver | Is it approved by a human or automatically? |
| turn id | Connect to which agent turn it belongs to |
4. Why transcripts should not be viewed as chat logs
Transcript is not a “save transcript”. Event log to reproduce agent execution.
A good transcript should be able to answer the following questions:
- What input did the user send?
- What tools did the model request?
- What permission decisions did runtime make?
- What did the user approve?
- What were the tool results?
- What decision did the model make after looking at the results?
- At what point did costs and tokens increase?
Failure to answer these questions makes debugging, auditing, and recovery difficult.
5. Usage and cost accounting
A long-running agent can call a model multiple times, put back tool results, compress context, and perform retry. If you calculate the cost once at the end, the error will increase.
Therefore, usage and cost must be accumulated at the stream event stage.
| event | accounting processing |
|---|---|
| model request start | Request metadata history |
| usage update | Merge token/cache/reasoning usage |
| tool execution | Tool call count, external API cost recording |
| retry/fallback | Connect as a separate request |
| cancel | Confirmed usage to date |
| final | Create turn summary |
6. Safety layer in conceptual code
The code below is newly written code for explanation purposes.
# How to read: Conceptual code that describes runtime boundaries, not a clone of the actual implementation.class PermissionDecision: # Initializes runtime dependencies and state storage that the object will reference in later steps. def __init__(self, allowed, reason, requires_user=False): self.allowed = allowed self.reason = reason self.requires_user = requires_user # Whether or not it can be executed is determined in the order of policy, risk, automatic permission conditions, and user approval.async def evaluate_permission(tool, args, runtime): if runtime.policy.denies(tool, args): return PermissionDecision(False, "explicit_deny") risk = classify_risk(tool, args, runtime.workspace) if risk.level == "blocked": return PermissionDecision(False, risk.reason) if runtime.policy.auto_allows(tool, args, risk): return PermissionDecision(True, "auto_allow") user_choice = await runtime.shell.ask_approval( title=f"Approve execution of {tool.name}", body=build_risk_explanation(tool, args, risk), ) if user_choice == "deny": return PermissionDecision(False, "user_denied") return PermissionDecision(True, f"user_{user_choice}") # Permission decisions are left on the ledger and only permitted tools are actually executed.async def guarded_tool_execution(request, runtime): decision = await evaluate_permission(request.tool, request.args, runtime) await runtime.ledger.write("permission", { "tool": request.tool.name, "decision": decision.allowed, "reason": decision.reason, "turn": runtime.current_turn_id, }) if not decision.allowed: return ToolResult.denied(request.id, decision.reason) result = await runtime.tools.execute_without_rechecking(request) await runtime.ledger.write("tool_result", result.audit_summary()) return resultAlthough the authority judgment and record are separate, they share the same event. This will allow you to later explain “why it was done”.
7. AI utilization developer perspective
Developers using AI tools should ensure that:
| question | reason |
|---|---|
| Do you require approval before writing files? | Prevent unwanted changes |
| Does it display and execute shell commands? | Confirm critical command |
| Can you manage always-allow rules? | Avoid excessive automation |
| Can I check the transcript? | Auditing and Debugging |
| Can I see costs/token usage? | budget management |
| Is it easy to rollback after failure? | Practical stability |
If your team introduces it, these questions will soon become the adoption criteria.
8. Agent developer checklist
# How to read: The items below are summarized examples to quickly check the action flow.Permission / Transcript / Cost Checklist [ ] Authorization judgment is designed as a layered gate rather than a single if.[ ] explicit deny and sensitive operation checks are run before auto-allow.[ ] The approval UI and policy engine are separated.[ ] Permission denial also returns to model-visible tool result.[ ] transcript connects user input, model response, tool request, permission decision, and result.[ ] usage/cost is updated even in the middle of the stream.[ ] Accounting is maintained even in cancel/retry/fallback situations.[ ] When restoring a session, the transcript and cost state are restored together.9. Operational example: Binding approvals and costs to the same run ledger
In long agent operations, it is easy to miss the cause if you look at permission decisions and cost records separately. For example, if the agent modified 3 files, ran the test 4 times, and even used a provider fallback, it is not possible to know why the cost increased based on the final answer alone. In run ledger, permission decision, tool call, transcript checkpoint, and usage snapshot must be tied to the same trace ID.
| record | Questions to check later |
|---|---|
| permission decision | What write operations have the user approved? |
| transcript checkpoint | What observations did the model make its next decision? |
| usage snapshot | At what turn did the cost increase? |
| cost limit event | Did you stop before you went over budget? |
A failure example is a structure that leaves cost tracking only to the billing dashboard. You can know the total amount at the end of the month, but it is difficult to find out which task, prompt version, or tool retry created the cost. Conversely, if you store the full text of the token or sensitive prompt in the run ledger, a security problem arises. What should be saved is not the entire original text, but summary values that can be judged, such as model, prompt version, input/output token, cached token, and tool retry count.
10. Closing Q&A
Q1. Wouldn’t asking for permission too often deteriorate usability?
you're right. So layered permission is needed. Safe read-only operations can be automatically allowed, while dangerous write/shell/network operations must be approved.
Q2. Should the transcript save all contents as is?
no. Sensitive information should be masked or summarized. The important thing is not to unconditionally save the original, but to leave the sequence of events and reasons for decisions recoverable.
Q3. Can cost tracking be left out of MVP?
This is possible for a personal demo, but if you are considering introducing a long-running agent or a team, it is better to include a minimum usage snapshot at the beginning. If you attach it later, it is difficult to restore the connection of request, retry, and cancellation.
final summary
When analyzing Claude Code-type agents from a runtime perspective, there is only one final question.
Can this agent be automated, or can it be automated safely?
Permissions, transcript, and cost are the key layers to answer this question. Without these three, the agent may be fast, but it is unreliable. Conversely, if these three are designed from scratch, even a small agent can grow to product level.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.