AI Agent 이야기를 하다 보면 어느 순간 온톨로지, 지식그래프, GraphRAG, 정책 엔진 같은 단어가 함께 등장합니다.
그런데 여기서 바로 오해가 생깁니다.
AI Agent라서 온톨로지가 필요한 걸까요?
아니면 조직 자동화가 복잡해지기 때문에 온톨로지가 필요한 걸까요?
이 글의 결론은 후자에 가깝습니다.
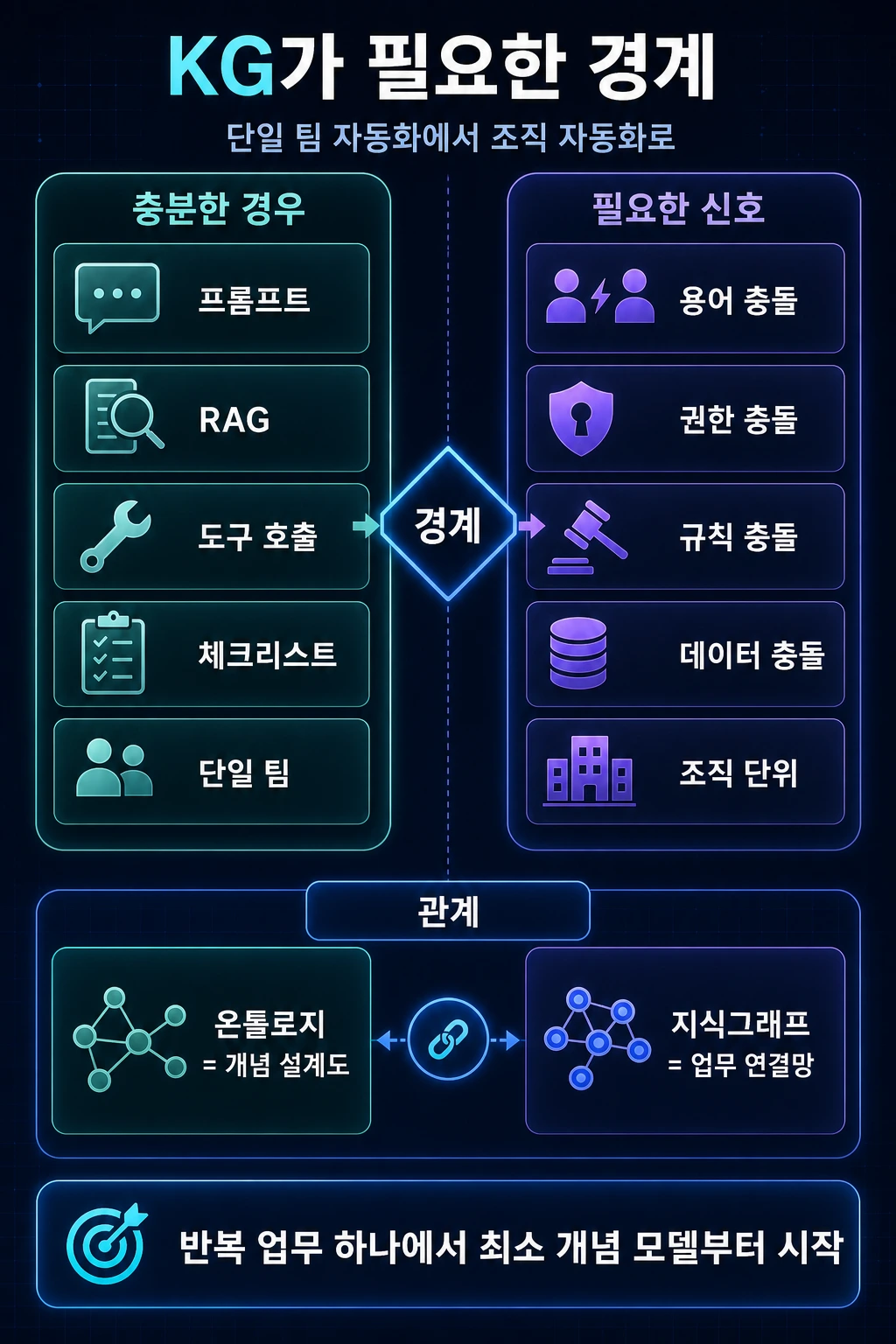
AI Agent라서 온톨로지와 지식그래프가 필요한 것이 아닙니다. 개인 업무나 소규모 팀 자동화에서는 프롬프트, 템플릿, RAG, 명확한 도구 호출만으로도 충분한 경우가 많습니다.
하지만 자동화 범위가 여러 팀, 여러 시스템, 여러 업무 규칙, 여러 승인 흐름으로 커지는 순간부터는 문제가 달라집니다. 같은 단어를 부서마다 다르게 쓰고, 같은 고객을 시스템마다 다른 ID로 관리하며, 같은 액션이라도 권한과 정책에 따라 실행 가능 여부가 달라집니다.
그때부터 온톨로지와 지식그래프는 선택적 장식이 아니라, 조직 단위 AI 자동화를 안정적으로 운영하기 위한 의미 기반 인프라가 됩니다.
분석 기준일: 2026-05-01
주요 참고자료: OpenAI Practical Guide to Building Agents, Anthropic Building Effective Agents, W3C OWL/SHACL 문서
분석 범위: AI Agent 개념 설명이 아니라, 팀 자동화가 조직 자동화로 확장될 때 온톨로지/KG가 필요한 이유
핵심 요약
- AI Agent 자체가 온톨로지/KG를 요구하는 것은 아닙니다. 단순 업무 자동화는 프롬프트, RAG, 도구 호출, 체크리스트만으로도 충분할 수 있습니다.
- 온톨로지/KG가 강력해지는 지점은 조직 단위 자동화입니다. 여러 팀의 용어, 권한, 업무 규칙, 데이터 소스가 충돌하기 시작할 때 필요해집니다.
- 온톨로지는 조직에서 쓰는 개념과 관계의 설계도이고, 지식그래프는 그 설계도에 따라 연결된 실제 업무 데이터의 연결망입니다.
- 처음부터 전사 온톨로지를 만들 필요는 없습니다. 반복되는 핵심 업무 하나에서 최소 개념 모델을 만들고 확장하는 편이 현실적입니다.
- 실무 판단 기준은 단순합니다. “검색을 잘하고 싶은가?”보다 “업무 의미를 일관되게 해석하고, 권한과 규칙을 검증해야 하는가?”를 먼저 봐야 합니다.
1. AI Agent와 온톨로지를 바로 연결하면 생기는 오해
요즘 AI Agent를 설명하는 글이나 세미나를 보면, 에이전트를 곧바로 온톨로지나 지식그래프와 연결하는 경우가 많습니다.
물론 방향성 자체는 틀리지 않습니다. 기업 업무 자동화에서는 결국 고객, 계약, 상품, 정책, 승인, 권한, 문서, 시스템 같은 객체들이 서로 연결되어야 합니다. 이 연결을 제대로 모델링하려면 온톨로지와 지식그래프가 강력한 도구가 됩니다.
다만 순서가 중요합니다.
AI Agent라서 온톨로지/KG가 필요한 것이 아니라, 조직 단위 자동화에서 의미 불일치·권한·규칙·데이터 연결 문제가 커지기 때문에 필요해집니다.
OpenAI의 에이전트 가이드도 복잡한 구조를 처음부터 만들기보다, 명확한 도구와 가드레일을 갖춘 에이전트에서 시작하고, 복잡도가 커질 때 프롬프트 템플릿, 정책 변수, 멀티에이전트 구조 등을 고려하라고 설명합니다. Anthropic 역시 에이전트 구현을 설명할 때 augmented LLM에서 출발해 단순한 조합형 워크플로우를 거쳐 복잡한 에이전트로 점진적으로 확장하는 흐름을 제시합니다.
실무적으로 해석하면 이렇습니다.
# 예시 구조처음부터 전사 온톨로지를 만들지 않는다.먼저 단일 업무 자동화가 되는지 본다.그다음 의미 불일치, 권한 검증, 규칙 검증 문제가 반복될 때온톨로지와 지식그래프를 도입한다.이 관점이 중요합니다. 온톨로지와 지식그래프를 너무 일찍 도입하면 프로젝트가 데이터 모델링 사업으로 커져버립니다. 반대로 너무 늦게 도입하면 AI Agent가 여러 시스템을 연결하는 순간부터 오해와 권한 사고가 쌓입니다.
결국 핵심은 “필요한가?”보다 **“언제 필요한가?”**입니다.
2. 개인 자동화, 팀 자동화, 조직 자동화는 무엇이 다른가
AI 자동화는 범위에 따라 필요한 구조가 달라집니다.
개인 업무에서는 LLM이 문서를 요약하고, 코드 초안을 만들고, 반복 작업을 도와주는 것만으로도 충분한 가치가 있습니다. 이때 필요한 것은 좋은 프롬프트, 템플릿, 예시, 간단한 체크리스트입니다.
팀 단위로 가면 조금 더 복잡해집니다. 회의록, 티켓, 코드, 문서, 배포 기록이 연결됩니다. 이때는 RAG, 팀 지식베이스, 워크플로우 정의, 도구 레지스트리가 필요해집니다.
조직 단위로 가면 문제가 다시 바뀝니다. 이제 단순히 “문서를 찾아 답하기”가 아니라, 여러 팀이 같은 업무 객체를 같은 의미로 이해하고, 같은 규칙에 따라 실행하는지가 중요해집니다.
| 단계 | 자동화 범위 | 필요한 구조 |
|---|---|---|
| 개인/소규모 팀 | 문서 요약, 코드 보조, 반복 리포트 생성 | 프롬프트, 템플릿, 체크리스트 |
| 팀 단위 | 회의록, 티켓, 코드, 문서 연결 | RAG, 팀 지식베이스, 워크플로우 정의 |
| 여러 팀 확장 | 같은 고객/프로젝트/업무를 여러 팀이 다르게 해석 | 공통 용어집, 업무 개념 모델, 역할 모델 |
| 조직 단위 | 부서·시스템·문서·정책·승인 흐름 통합 | 온톨로지, 지식그래프, 검증 규칙 |
| 전사 AI 운영체계 | 여러 에이전트가 같은 조직 지식을 기반으로 실행 | 엔터프라이즈 KG, 정책 엔진, provenance, 감사 로그 |
여기서 중요한 차이는 자동화의 대상이 작업에서 조직 의미 체계로 이동한다는 점입니다.
개인 자동화의 질문은 이런 식입니다.
# 예시 구조이 문서를 요약해줘.이 코드를 리팩터링해줘.이 회의록에서 액션 아이템을 뽑아줘.조직 자동화의 질문은 다릅니다.
# 예시 구조고객 A의 온보딩을 시작해줘.이 계약 변경을 진행할 수 있는지 확인해줘.이번 장애의 영향 고객과 보상 정책을 정리해줘.이 리포트를 발행해도 되는지 승인 조건을 검증해줘.두 번째 유형의 질문에는 단순 문서 검색보다 더 많은 것이 필요합니다. 고객이 누구인지, 계약 상태가 어떤지, 어떤 정책이 적용되는지, 요청자가 어떤 권한을 갖고 있는지, 근거 문서가 무엇인지, 실행 결과를 어디에 기록해야 하는지까지 연결해야 합니다.
이때부터 온톨로지와 지식그래프가 실무적으로 의미를 갖습니다.
3. 팀 단위에서는 왜 RAG와 워크플로우만으로 충분한가
팀 단위 AI 자동화에서는 대부분 다음 구조로 시작합니다.
# 예시 구조사용자 요청 ↓프롬프트 템플릿 ↓문서 검색 / RAG ↓도구 호출 ↓결과 요약예를 들어 개발팀 내부에서 “지난 스프린트 회고 요약해줘”라고 요청하면, 회의록과 티켓을 검색해 요약하면 됩니다. 고객지원팀 내부에서 “이번 주 반복 문의를 정리해줘”라고 요청하면, 상담 로그를 검색하고 빈도 높은 이슈를 묶으면 됩니다.
이 범위에서는 팀 구성원이 이미 암묵적 맥락을 공유합니다.
# 예시 구조우리 팀에서 말하는 고객은 무엇인지우리 팀에서 완료는 어떤 상태인지우리 팀에서 긴급은 어느 정도의 우선순위인지우리 팀에서 승인자는 누구인지LLM이 약간 애매하게 답해도 사람이 맥락으로 보정할 수 있습니다. 또한 실행 대상이 제한적이면 잘못된 도구 호출의 피해도 비교적 작습니다.
따라서 팀 단위에서는 다음 구성만으로도 충분한 경우가 많습니다.
| 구성 요소 | 역할 | 예시 |
|---|---|---|
| 프롬프트 템플릿 | 반복 업무의 출력 형식 고정 | 회의록 요약, 코드 리뷰, 리포트 초안 |
| RAG | 관련 문서 검색 | 위키, Notion, Confluence, Jira, GitHub 이슈 |
| 도구 호출 | 정해진 액션 실행 | 티켓 생성, 슬랙 알림, 문서 생성 |
| 체크리스트 | 사람이 확인할 항목 정리 | 배포 전 확인, 보안 검토, 승인 여부 |
| 로그 | 실행 이력 저장 | 누가 언제 무엇을 요청했는지 기록 |
이 단계에서는 굳이 온톨로지를 만들 필요가 없습니다.
실무 판단
업무 범위가 한 팀 안에서 닫히고, 규칙이 단순하고, 사람이 최종 판단을 계속 한다면 RAG와 워크플로우 자동화부터 시작하는 것이 맞습니다.
온톨로지를 너무 일찍 도입하면 실제 자동화보다 개념 정리 회의가 먼저 커질 수 있습니다. 이 경우 프로젝트가 “AI 자동화”가 아니라 “전사 용어 표준화 사업”처럼 흘러갈 위험이 있습니다.
4. 조직 단위가 되면 왜 의미 불일치가 커지는가
문제는 여러 팀이 연결되는 순간부터 시작됩니다.
팀 안에서는 암묵적으로 통하던 단어가, 조직 전체에서는 서로 다른 의미를 갖습니다. 특히 영업, 개발, 운영, 재무, 보안, 법무가 같은 객체를 다룰 때 이런 문제가 자주 발생합니다.
| 용어 | 영업팀 의미 | 개발팀 의미 | 운영팀 의미 |
|---|---|---|---|
| 고객 | 구매 가능성이 있는 리드 또는 계정 | 서비스 계정 소유자 | 장애 영향 대상 |
| 완료 | 계약 체결 | 배포 완료 | 고객 확인 완료 |
| 긴급 | 이번 주 안에 처리 | 오늘 배포 필요 | 즉시 조치 필요 |
| 승인 | 팀장 승인 | PR 승인 | 결재/컴플라이언스 승인 |
| 이슈 | 영업 기회 리스크 | 버그 또는 기술 문제 | 장애 또는 고객 불만 |
사람끼리는 회의하면서 조정할 수 있습니다. 하지만 AI Agent는 문장을 그럴듯하게 생성할 수 있어도, 조직 내부 용어의 미묘한 차이를 항상 안정적으로 구분하지 못합니다.
예를 들어 사용자가 이렇게 요청했다고 해보겠습니다.
# 예시 구조고객 A 온보딩 완료 처리해줘.영업팀의 “완료”는 계약 체결일 수 있습니다. 개발팀의 “완료”는 계정 생성과 초기 배포일 수 있습니다. 운영팀의 “완료”는 고객 확인과 인수인계까지 끝난 상태일 수 있습니다.
이 상태에서 AI Agent가 CRM, Jira, Slack, 결재 시스템, 문서 시스템을 모두 호출할 수 있다면 위험합니다. 단어 하나의 해석 차이가 실제 시스템 액션으로 이어질 수 있기 때문입니다.
조직 단위 자동화에서는 다음 문제가 함께 커집니다.
| 문제 | 설명 | 예시 |
|---|---|---|
| 의미 불일치 | 같은 단어를 팀마다 다르게 사용 | 완료, 승인, 고객, 긴급 |
| 엔티티 불일치 | 같은 객체가 시스템마다 다르게 저장 | 고객명, 계정 ID, 계약 ID |
| 권한 불일치 | 요청자와 실행자의 권한이 다름 | 승인권 없는 계약 변경 |
| 규칙 불일치 | 부서별 업무 규칙이 충돌 | 할인 정책, 보안 심사, 법무 검토 |
| 근거 누락 | AI가 어떤 문서에 근거했는지 추적 어려움 | 리포트, 승인, 공지 발행 |
| 실행 추적 불가 | 누가 어떤 근거로 어떤 액션을 했는지 모름 | 감사 로그 부재 |
이 문제들은 단순히 “LLM을 더 좋은 모델로 바꾸면 해결되는 문제”가 아닙니다. 모델의 언어 이해 능력이 좋아져도, 조직의 의미 체계가 명시되어 있지 않으면 해석 기준이 흔들립니다.
결국 조직 자동화에서 필요한 것은 더 긴 프롬프트만이 아닙니다. 조직의 개념, 관계, 상태, 권한, 규칙, 근거를 구조화한 의미 계층이 필요합니다.
5. 온톨로지는 조직 언어의 설계도다
온톨로지는 어렵게 들리지만, 실무적으로는 이렇게 이해하면 됩니다.
온톨로지는 조직에서 쓰는 개념의 뜻과 관계를 명시한 설계도입니다.
예를 들어 고객 온보딩 업무를 자동화한다고 하면, 다음과 같은 개념이 등장합니다.
# 예시 구조CustomerContractSecurityReviewOnboardingChecklistCSMProjectTaskDocumentPolicyPermissionApprovalEvidenceAction온톨로지는 이 개념들이 무엇이고, 서로 어떤 관계인지 정의합니다.
# 예시 구조Customer has ContractContract has StatusCustomer assignedTo CSMOnboardingChecklist appliesTo IndustryAction requires PermissionDecision basedOn EvidencePolicy constrains ActionW3C의 OWL 문서는 온톨로지를 클래스, 속성, 관계, 카디널리티, 동등성, 분리성 같은 어휘로 표현할 수 있게 해줍니다. 즉 “고객은 계약을 가질 수 있다”, “계약은 상태를 가진다”, “특정 액션은 특정 권한을 필요로 한다” 같은 지식을 기계가 처리할 수 있는 형태로 표현할 수 있습니다.
온톨로지가 있으면 AI Agent는 단순히 문장만 보고 판단하지 않습니다. 요청 문장을 조직의 개념 모델에 매핑해서 해석할 수 있습니다.
# 예시 구조사용자: 고객 A 온보딩 시작해줘 해석:- 고객 A는 Customer인가?- 고객 A의 Contract 상태는 무엇인가?- 온보딩에 필요한 SecurityReview가 있는가?- 요청자는 OnboardingStartAction을 실행할 Permission이 있는가?- 적용해야 할 Policy는 무엇인가?온톨로지의 목적은 AI에게 모든 것을 알려주는 것이 아닙니다. 목적은 더 좁고 실용적입니다.
AI가 업무 세계를 해석할 때 흔들리지 말아야 할 개념과 관계를 고정하는 것.
이것이 조직 자동화에서 온톨로지가 필요한 이유입니다.
6. 지식그래프는 실제 업무 데이터의 연결망이다
온톨로지가 설계도라면, 지식그래프는 그 설계도를 따라 연결된 실제 데이터입니다.
온톨로지가 이렇게 말한다면,
# 예시 구조Customer has ContractContract approvedBy PersonContract basedOn DocumentAction requires Permission지식그래프는 이렇게 채워집니다.
# 예시 구조고객A --hasContract--> 계약B계약B --approvedBy--> 김OO계약B --basedOn--> 보안심사문서C김OO --belongsTo--> 엔터프라이즈영업팀온보딩시작Action --requiresPermission--> OnboardingManagerRole즉, 지식그래프는 고객, 계약, 담당자, 문서, 티켓, 시스템, 정책, 승인 이력 같은 실제 업무 객체를 연결합니다.
| 구분 | 역할 | 예시 |
|---|---|---|
| 온톨로지 | 업무 세계의 개념 설계도 | 고객은 계약을 가질 수 있다. 액션은 권한을 필요로 한다. |
| 지식그래프 | 실제 업무 데이터의 연결망 | A고객 — B계약 — C담당자 — D문서 — E티켓 |
| 검증 규칙 | 데이터와 액션의 조건 검사 | 승인 없는 계약 변경 불가. 근거 없는 리포트 발행 불가. |
조직 자동화에서 지식그래프가 중요한 이유는 “데이터를 예쁘게 연결하기 위해서”가 아닙니다.
AI Agent가 실제로 업무를 실행하려면, 다음 질문에 안정적으로 답해야 하기 때문입니다.
# 예시 구조이 고객은 누구인가?이 계약은 어떤 상태인가?이 문서는 어떤 결정의 근거인가?이 사용자는 어떤 팀에 속하는가?이 액션은 어떤 권한이 필요한가?이 정책은 어떤 조건에서 적용되는가?이 실행 결과를 어디에 기록해야 하는가?RAG는 관련 문서 조각을 찾는 데 강합니다. 하지만 여러 시스템의 객체와 관계를 따라가며 상태와 권한을 검증하는 일은 별도의 구조가 필요합니다.
이때 지식그래프는 조직의 업무 객체를 연결하는 기반이 됩니다.
7. 온톨로지/KG가 필요한 상황과 과한 상황
온톨로지와 지식그래프는 강력하지만, 모든 프로젝트에 필요한 것은 아닙니다.
다음 상황에서는 도입 가치가 큽니다.
| 상황 | 왜 필요한가 | 예시 |
|---|---|---|
| 여러 팀이 같은 객체를 다르게 해석 | 공통 의미 모델이 필요 | 고객, 계약, 승인, 완료 |
| 여러 시스템의 데이터를 연결 | 엔티티 정합성이 필요 | CRM, ERP, Jira, Notion, Slack |
| 권한과 정책 검증이 중요 | 실행 전 조건 검사가 필요 | 계약 변경, 할인 승인, 고객 공지 |
| 근거 추적이 필요 | provenance와 감사 로그가 필요 | 리포트 발행, 의사결정, 규정 준수 |
| 질문이 여러 객체를 가로지름 | 관계 기반 검색이 필요 | 고객-계약-이슈-정책 연결 |
| 여러 에이전트가 같은 조직 지식을 사용 | 공유 의미 계층이 필요 | 영업 Agent, 운영 Agent, 보안 Agent |
반대로 다음 상황에서는 과할 수 있습니다.
| 상황 | 더 단순한 대안 |
|---|---|
| 단일 팀 내부 업무 | 프롬프트 템플릿 + RAG |
| 단일 시스템 조회/실행 | API 호출 + 워크플로우 |
| 사람이 항상 최종 승인 | 체크리스트 + 로그 |
| 용어 충돌이 거의 없음 | 팀 위키 + 태그 체계 |
| 규칙이 단순함 | if/else 정책 변수 |
| PoC 단계에서 검증할 것이 많음 | 먼저 작은 자동화로 ROI 확인 |
주의
온톨로지/KG를 “있으면 멋진 기술”로 도입하면 실패하기 쉽습니다.
도입 기준은 기술 유행이 아니라, 의미 불일치·데이터 연결·권한 검증·근거 추적 문제가 실제로 반복되는지입니다.
실무적으로는 다음 질문에 답해보면 됩니다.
# 예시 구조이 업무는 여러 팀의 용어가 충돌하는가?이 업무는 여러 시스템의 객체를 연결해야 하는가?이 업무는 권한과 정책 검증이 필요한가?이 업무는 실행 근거를 나중에 감사해야 하는가?이 업무는 실패했을 때 비용이나 리스크가 큰가?여기서 “예”가 많을수록 온톨로지와 지식그래프의 필요성이 커집니다.
8. 예시: “신규 고객 온보딩 시작해줘”
이제 구체적인 예시를 보겠습니다.
사용자가 AI Agent에게 이렇게 요청합니다.
# 예시 구조고객 A 온보딩 시작해줘.온톨로지와 지식그래프가 없는 경우, Agent는 보통 문서 검색과 프롬프트에 의존합니다.
# 예시 구조관련 문서 검색→ 온보딩 절차 요약→ 체크리스트 생성→ 담당자에게 메시지 전송단순한 팀 업무라면 이것만으로도 충분할 수 있습니다.
하지만 조직 단위에서는 Agent가 더 많은 것을 확인해야 합니다.
# 예시 구조고객 A는 어떤 조직인가?계약 상태는 완료인가?보안 심사는 통과했는가?산업군에 따라 다른 절차가 있는가?담당 CSM은 누구인가?온보딩 체크리스트는 어떤 버전인가?요청자는 온보딩을 시작할 권한이 있는가?생성한 문서와 액션의 근거는 무엇인가?실행 결과를 어떤 시스템에 기록해야 하는가?이 질문들은 단순 문서 검색만으로는 안정적으로 처리하기 어렵습니다.
온톨로지/KG가 있으면 흐름이 달라집니다.
# 예시 구조사용자 요청 ↓의도 파악 ↓온톨로지로 업무 개념 해석 ↓지식그래프로 관련 데이터 조회 ↓권한/정책/상태 검증 ↓필요한 도구 실행 ↓실행 결과와 근거를 다시 그래프에 기록예를 들어 그래프에는 다음과 같은 연결이 있을 수 있습니다.
# 예시 구조Customer:A → hasContract → Contract:B → assignedTo → Person:CSM_C → belongsToIndustry → Industry:Finance Contract:B → hasStatus → Signed → basedOn → Document:ContractDoc_D SecurityReview:E → appliesTo → Customer:A → hasStatus → Passed Action:StartOnboarding → requiresPermission → Permission:OnboardingStart → constrainedBy → Policy:FinanceCustomerOnboardingPolicy이렇게 되면 Agent는 “온보딩 시작”이라는 문장을 조직의 실제 업무 객체와 연결해 판단할 수 있습니다.
결국 차이는 이것입니다.
| 방식 | 동작 | 리스크 |
|---|---|---|
| 프롬프트/RAG 중심 | 관련 문서를 찾아 절차를 요약 | 상태·권한·정책 검증이 약함 |
| 온톨로지/KG 중심 | 업무 객체와 관계를 조회하고 조건을 검증 | 구축과 운영 비용이 있음 |
따라서 조직 단위 자동화에서는 RAG와 KG를 경쟁 관계로 볼 필요가 없습니다. RAG는 문서 맥락을 제공하고, KG는 업무 객체와 관계를 제공하며, 검증 규칙은 실행 가능 여부를 판단합니다.
9. 작은 온톨로지로 시작하는 방법
처음부터 전사 온톨로지를 만들 필요는 없습니다. 오히려 그렇게 시작하면 실패 가능성이 큽니다.
현실적인 순서는 다음과 같습니다.
# 예시 구조1. 자동화할 핵심 업무 1개 선정2. 그 업무의 핵심 질문 정의3. 반복 등장하는 개념 추출4. 최소 온톨로지 작성5. 기존 DB/문서/티켓/API와 연결6. 검증 규칙 추가7. 에이전트 실행 로그와 결과를 기록8. 실패 로그를 분석해 모델 개선9. 다른 팀 업무로 확장처음에는 다음 정도의 모델이면 충분합니다.
# 예시 구조Class:- Project- Task- Document- Person- Team- System- Permission- Policy- Decision- Evidence- Action관계도 단순하게 시작할 수 있습니다.
# 예시 구조Person belongsTo TeamTask belongsTo ProjectTask requires DocumentDecision basedOn EvidenceAction executedBy AgentAction requires PermissionPolicy constrains ActionSystem owns Data이 정도만 있어도 AI Agent는 단순 챗봇에서 벗어나 “업무 상태를 이해하고, 조건을 확인하고, 근거를 남기며 실행하는 시스템”에 가까워집니다.
실무 팁
첫 온톨로지는 예쁘게 만드는 것이 목표가 아닙니다.
자동화 실패를 줄이는 데 필요한 개념만 남기는 것이 목표입니다.
작게 시작할 때 가장 좋은 기준은 Competency Question입니다. 이 그래프가 답해야 하는 질문을 먼저 적는 방식입니다.
예를 들면 다음과 같습니다.
# 예시 구조이 고객의 현재 계약 상태는 무엇인가?이 액션을 실행할 수 있는 사용자는 누구인가?이 결정의 근거 문서는 무엇인가?이 정책은 어떤 고객군에 적용되는가?이 업무가 완료되려면 어떤 조건이 필요한가?질문이 정해지면 필요한 클래스와 관계도 자연스럽게 줄어듭니다.
10. 실전 체크리스트
조직에서 AI Agent 자동화를 추진하고 있다면, 온톨로지/KG 도입 전에 아래 체크리스트를 먼저 확인해보는 것이 좋습니다.
# 예시 구조적용 전 체크리스트 [ ] 자동화할 핵심 업무가 1개로 좁혀져 있다.[ ] 이 업무에서 반복적으로 등장하는 핵심 객체가 정리되어 있다.[ ] 같은 용어를 팀마다 다르게 쓰는 문제가 확인되었다.[ ] 여러 시스템의 데이터를 연결해야 한다.[ ] 실행 전 권한 또는 정책 검증이 필요하다.[ ] 결과에 대한 근거 문서와 감사 로그가 필요하다.[ ] 단순 RAG와 워크플로우로는 실패가 반복된다.[ ] 도메인 전문가가 개념 정의를 검토할 수 있다.[ ] 처음부터 전사 범위가 아니라 작은 업무 범위로 시작한다.[ ] 실패 로그를 보고 온톨로지를 개선할 운영 절차가 있다.이 중 절반 이상이 해당된다면 온톨로지와 지식그래프를 검토할 만합니다.
반대로 대부분 해당되지 않는다면, 먼저 RAG와 워크플로우 자동화부터 시작하는 편이 낫습니다.
11. Q&A
Q1. 모든 AI Agent에 온톨로지가 필요한가요?
아닙니다. 단일 팀 업무, 단일 시스템 자동화, 단순 조회/요약 업무에는 과할 수 있습니다. 먼저 프롬프트, RAG, 도구 호출, 체크리스트로 충분한지 확인하는 것이 좋습니다.
Q2. RAG를 쓰면 지식그래프가 필요 없나요?
아닙니다. 역할이 다릅니다. RAG는 관련 문서 조각을 찾는 데 강하고, 지식그래프는 객체와 관계를 연결하는 데 강합니다. 조직 자동화에서는 둘을 함께 쓰는 경우가 많습니다.
Q3. 온톨로지는 누가 만들어야 하나요?
도메인 전문가, AI/데이터 엔지니어, 업무 담당자가 함께 만들어야 합니다. 개발자만 만들면 업무 의미가 빠지고, 현업만 만들면 실행 가능한 구조가 되기 어렵습니다.
Q4. 전사 KG를 먼저 만들어야 하나요?
아닙니다. 핵심 업무 하나에서 시작하는 것이 좋습니다. 예를 들어 고객 온보딩, 계약 변경, 장애 대응, 리포트 발행처럼 반복성과 리스크가 큰 업무를 고릅니다.
Q5. 기존 DB를 모두 그래프 DB로 옮겨야 하나요?
꼭 그렇지는 않습니다. 기존 RDB, API, 문서 저장소를 그대로 두고, 그 위에 의미 계층을 얹는 방식도 가능합니다. 실제 도입 전략은 3편에서 자세히 다룹니다.
12. 참고자료와 불확실성
참고자료
- OpenAI, A practical guide to building agents
- Anthropic, Building Effective AI Agents
- W3C, OWL Web Ontology Language Overview
- W3C, OWL Web Ontology Language Use Cases and Requirements
- W3C, Shapes Constraint Language SHACL
확인된 사실
- OpenAI와 Anthropic 모두 에이전트 설계에서 처음부터 복잡한 구조를 강제하기보다, 단순하고 조합 가능한 패턴에서 출발하는 접근을 설명합니다.
- W3C OWL은 클래스, 속성, 관계, 제약 등을 표현할 수 있는 온톨로지 언어입니다.
- SHACL은 RDF 그래프가 특정 조건을 만족하는지 검증하기 위한 표준입니다.
작성자의 해석
- 온톨로지/KG는 AI Agent의 필수 출발점이 아니라, 조직 단위 자동화에서 의미 불일치와 검증 문제가 커질 때 필요한 구조입니다.
- 팀 단위 자동화와 조직 단위 자동화는 기술 스택 차이보다 운영 리스크 차이가 큽니다.
불확실성
- 조직별 데이터 구조, 권한 체계, 업무 규칙에 따라 필요한 온톨로지의 깊이는 크게 달라질 수 있습니다.
- GraphRAG나 KG 기반 검색이 일반 RAG보다 항상 좋은 것은 아닙니다. 질문 유형과 데이터 구조에 따라 효과가 달라집니다.
마무리
정리하면, AI Agent에 온톨로지와 지식그래프가 무조건 필요한 것은 아닙니다.
개인 업무나 팀 단위 자동화에서는 프롬프트, 템플릿, RAG, 도구 호출, 체크리스트만으로도 충분한 경우가 많습니다.
하지만 여러 팀, 여러 시스템, 여러 규칙을 연결하는 조직 단위 자동화로 확장하면 이야기가 달라집니다. 이때부터는 “문서를 잘 찾는 AI”보다 “조직의 업무 의미를 일관되게 해석하고, 권한과 규칙을 검증하며, 근거를 남기는 AI”가 필요해집니다.
한 줄로 정리하면 이렇습니다.
온톨로지와 지식그래프는 AI Agent의 출발점이 아니라, 조직 단위 AI 자동화의 확장성과 신뢰성을 확보하기 위한 의미 기반 인프라입니다.
다음 편에서는 온톨로지, 지식그래프, RAG, GraphRAG, SHACL, SPARQL이 각각 어떤 역할을 하는지 아키텍처 관점에서 정리하겠습니다.
요약 카드
- 한 줄 요약: 온톨로지/KG는 AI Agent의 출발점이 아니라 조직 단위 자동화의 의미 기반 인프라다.
- 추천 대상: AI 자동화를 팀에서 조직 단위로 확장하려는 개발자, AI TF, 플랫폼팀, CTO
- 비추천 대상: 단일 팀 내부 요약/검색/간단한 도구 호출만 필요한 팀
- 가장 중요한 판단 기준: 의미 불일치, 권한 검증, 정책 검증, 근거 추적이 반복되는가
- 가장 큰 리스크: 전사 온톨로지를 처음부터 만들려다 자동화 목표를 잃는 것
- 지금 바로 할 일: 자동화할 핵심 업무 1개와 그 업무가 답해야 할 질문을 먼저 정리하기
When talking about AI Agent, words such as ‘ontology’, ‘knowledge graph’,GraphRAG, and ‘policy engine’ appear together at some point.
But this is where a misunderstanding arises.
Does it need ontology because it is an AI Agent? Or are ontologies needed because organizational automation is becoming more complex?
The conclusion of this article is closer to the latter.
Because it is an AI Agent, ontology and knowledge graph are not required. In individual work or small team automation, prompts, templates, RAGs, and clear tool calls are often sufficient.
But the moment the scope of automation grows to include multiple teams, multiple systems, multiple business rules, and multiple approval flows, things change. The same word is used differently in each department, the same customer is managed with a different ID in each system, and even the same action can be executed differently depending on permissions and policies.
From then on, ontology and knowledge graph are not optional decorations, but become semantic-based infrastructure for stable operation of organizational-level AI automation.
Date of analysis: 2026-05-01 Key references: OpenAI Practical Guide to Building Agents, Anthropic Building Effective Agents, W3C OWL/SHACL document Scope of analysis: Rather than explaining the AI Agent concept, Why Ontology/KG is needed when team automation extends to organization automation
Key takeaways
- AI Agent itself does not require ontology/KG. Prompts, RAGs, tool calls, and checklists may be sufficient for simple task automation.
- Where Ontology/KG becomes powerful is in Organizational Unit Automation. This becomes necessary when terminology, permissions, business rules, and data sources from multiple teams begin to conflict.
- Ontology is a blueprint of concepts and relationships used in an organization, and the knowledge graph is a network of actual business data connected according to the blueprint.
- There is no need to create a transcription ontology from scratch. It is more realistic to create and expand a minimal conceptual model from one core repetitive task.
- The criteria for practical judgment are simple. Rather than “Do you want to be good at searching?”, you should first ask “Do you need to consistently interpret the meaning of the task and verify authority and rules?”
1. Misunderstandings that arise when directly connecting AI Agent and Ontology
These days, when you look at articles or seminars explaining AI Agents, they often directly connect the agent to ontology or knowledge graph.
Of course, the direction itself is not wrong. In corporate business automation, ultimately, objects such as customers, contracts, products, policies, approvals, permissions, documents, and systems must be connected to each other. To properly model this connection, ontologies and knowledge graphs become powerful tools.
However, the order is important.
Ontology/KG is not needed because it is an AI Agent, but it is needed because semantic inconsistency, authority, rules, and data connection problems increase in organizational unit automation.
OpenAI's agent guide also explains that rather than creating a complex structure from scratch, start with an agent with clear tools and guardrails, and consider prompt templates, policy variables, multi-agent structures, etc. when complexity increases. When explaining agent implementation, Anthropic also presents a flow that starts fromaugmented LLMand gradually expands to a complex agent through a simple combination workflow.
The practical interpretation is as follows.
# Example structureWe do not create a warrior ontology from scratch.First, see if a single task can be automated.Then, when problems with semantic inconsistency, authority verification, and rule verification are repeated,Introduce ontology and knowledge graph.This perspective is important. If ontology and knowledge graph are introduced too early, the project will grow into a data modeling business. Conversely, if it is introduced too late, misunderstandings and authority issues will accumulate from the moment the AI Agent connects multiple systems.
In the end, the key question is not “Do I need it?” but “When do I need it?”**
2. What is the difference between personal automation, team automation, and organizational automation?
AI automation requires different structures depending on its scope.
In private practice, an LLM can be valuable just to help you summarize documents, draft code, and iterate. All you need is good prompts, templates, examples, and simple checklists.
If you go by team, it gets a little more complicated. Meeting minutes, tickets, code, documents, and deployment records are linked. This is where RAGs, team knowledge bases, workflow definitions, and tool registries become necessary.
When we go to organizational units, the problem changes again. Now, rather than simply “finding and answering documents,” it becomes important whether multiple teams understand the same work object with the same meaning and execute it according to the same rules.
| step | Automation scope | structure needed |
|---|---|---|
| Individual/Small Team | Generate document summaries, code assistance, and iterative reports | Prompts, templates, checklists |
| team unit | Link meeting minutes, tickets, code, and documents | RAG, team knowledge base, workflow definition |
| Multiple team expansions | Different teams interpret the same customer/project/task differently | Common glossary, business concept model, role model |
| family | Integration of department, system, document, policy, and approval flow | Ontology, knowledge graph, verification rules |
| Company-wide AI operating system | Multiple agents run on the same organizational knowledge | Enterprise KG, policy engine, provenance, audit log |
The important difference here is that the target of automation moves from tasks to organizational semantics.
The question of personal automation goes like this.
# Example structurePlease summarize this document.Please refactor this code.Please select an action item from these meeting minutes.The question of organizational automation is different.
# Example structureStart onboarding Customer A.Please confirm if we can proceed with this contract change.Please explain the impact of this disruption on customers and compensation policies.Please verify the approval conditions to see if this report can be issued.The second type of question requires more than a simple document search. You need to connect who the customer is, what the contract status is, what policies apply, what permissions the requester has, what the supporting documents are, and where the execution results should be recorded.
From this point on, ontology and knowledge graph take on practical meaning.
3. Why are RAGs and workflows sufficient at the team level?
Most team-level AI automation starts with the following structure:
# Example structureuser request↓prompt template↓Document Search / RAG↓tool call↓Summary of ResultsFor example, if a member of the development team asks, “Please summarize the past sprint retrospective,” you can search the meeting minutes and tickets and summarize them. If the customer support team asks “Please sort out this week’s repeated inquiries,” you can search the consultation log and group the most frequent issues.
In this scope, team members already share an implicit context.
# Example structureWhat kind of customer does our team talk about?What is the status of completion for our team?How much of a priority is urgency for our team?Who are the approvers on my team?Even if the LLM answers are a bit ambiguous, humans can correct them with context. Additionally, if the execution target is limited, the damage from incorrect tool calls is relatively small.
Therefore, for teams, the following configuration is often sufficient:
| component | role | example |
|---|---|---|
| prompt template | Fix output format for repetitive tasks | Meeting minutes summaries, code reviews, report drafts |
| RAG | Search related documents | Wiki, Notion, Confluence, Jira, GitHub issues |
| tool call | Execute specified actions | Create tickets, Slack notifications, document creation |
| checklist | Organize items for people to check | Pre-deployment verification, security review, and approval |
| log | Save execution history | Record who requested what and when |
There is no need to create an ontology at this stage.
Practical Judgment If the scope of work is closed within a team, the rules are simple, and humans remain the final judge, it makes sense to start with RAG and workflow automation.
Introducing ontology too early can lead to more concept organizing meetings than actual automation. In this case, there is a risk that the project will flow like a “company terminology standardization project” rather than “AI automation.”
4. Why does semantic inconsistency increase as an organizational unit?
The problem begins the moment multiple teams connect.
Words that are used implicitly within a team have different meanings throughout the organization. This problem often arises especially when dealing with objects such as sales, development, operations, finance, security, and legal.
| terminology | Sales team meaning | development team meaning | Operation team meaning |
|---|---|---|---|
| customer | Leads or accounts that are likely to purchase | Service account owner | Disability Affected by |
| complete | conclusion of contract | Deployment complete | Customer confirmation completed |
| emergency | processed within this week | Deployment required today | Action required immediately |
| approval | Team leader approval | PR approved | Payment/Compliance Approval |
| issue | Sales Opportunity Risk | Bugs or technical issues | Failures or Customer Complaints |
People can make adjustments while meeting each other. However, even though AI Agents can generate plausible sentences, they cannot always reliably distinguish subtle differences in organizational terminology.
For example, let's say a user requests something like this:
# Example structurePlease complete customer A onboarding.“Done” for a sales team may be closing a contract. “Done” for the development team might be account creation and initial deployment. “Done” for the operations team may include customer confirmation and handover.
In this state, it is dangerous if the AI Agent can call CRM, Jira, Slack, payment system, and document system. This is because differences in the interpretation of a single word can lead to actual system actions.
The following challenges grow with organizational unit automation:
| problem | explanation | example |
|---|---|---|
| meaning mismatch | Different teams use the same word differently | Completed, Approved, Customer, Urgent |
| entity mismatch | The same object is stored differently in each system | Customer name, account ID, contract ID |
| Permission mismatch | Requester and executor have different permissions | Contract changes without approval rights |
| rule mismatch | Conflicting departmental work rules | Discount policy, security screening, legal review |
| missing evidence | Difficulty tracking which document the AI was based on | Issuance of reports, approvals and notices |
| No execution traceability | I don't know who took what action and on what basis. | Absence of audit log |
These problems are not simply “problems that can be solved by replacing LLM with a better model.” Even if a model's ability to understand language improves, its interpretation standards become unstable if the semantics of the organization are not specified.
After all, longer prompts aren't the only thing you need when it comes to organizational automation. A semantic hierarchy is needed to structure the organization's concepts, relationships, status, authority, rules, and rationale.
5. Ontology is the blueprint of an organizational language
Ontology may sound difficult, but in practice, it can be understood this way.
Ontology is a blueprint that specifies the meaning and relationships of concepts used in an organization.
For example, when it comes to automating customer onboarding tasks, the following concepts come into play:
# Example structureCustomerContractSecurityReviewOnboardingChecklistCSMProjectTaskDocumentPolicyPermissionApprovalEvidenceActionOntology defines what these concepts are and how they relate to each other.
# Example structureCustomer has ContractContract has StatusCustomer assignedTo CSMOnboardingChecklist appliesTo IndustryAction requires PermissionDecision basedOn EvidencePolicy constrains ActionW3C's OWL document allows ontologies to be expressed in terms of vocabulary such as classes, properties, relationships, cardinality, equality, and separability. In other words, knowledge such as “Customers can have contracts,” “Contracts have state,” and “Specific actions require specific permissions” can be expressed in a form that can be processed by machines.
With ontology, AI Agent does not simply look at sentences and make judgments. Request statements can be interpreted by mapping them to a conceptual model of the organization.
# Example structureUser: Start onboarding Customer A analysis:- Is Customer A a Customer?- What is Customer A’s contract status?- Is there a SecurityReview required for onboarding?- Does the requester have permission to execute OnboardingStartAction?- What policy should be applied?The purpose of ontology is not to tell AI everything. The purpose is narrower and more practical.
Fixing concepts and relationships that cannot be shaken when AI interprets the world of work.
This is why ontology is needed in organizational automation.
6. Knowledge graph is a network of actual business data
If ontology is a blueprint, the knowledge graph is actual data connected according to the blueprint.
If ontology says this,
# Example structureCustomer has ContractContract approvedBy PersonContract basedOn DocumentAction requires PermissionThe knowledge graph is filled like this.
# Example structureCustomer A --hasContract- to Contract BContract B --approvedBy- to Kim OOContract B --basedOn- to Security Review Document CKim OO --belongsTo- to Enterprise Sales TeamStart OnboardingAction --requiresPermission- to OnboardingManagerRoleIn other words, the knowledge graph connects actual business objects such as customers, contracts, personnel, documents, tickets, systems, policies, and approval history.
| division | role | example |
|---|---|---|
| Ontology | Conceptual blueprint of the world of work | Customers can have contracts. Actions require permission. |
| knowledge graph | Network of actual business data | Customer A — Contract B — Person in charge C — Document D — E ticket |
| Validation Rules | Condition checking of data and actions | No changes to the contract without approval. It is impossible to issue unfounded reports. |
The reason why knowledge graphs are important in organizational automation is not “to connect data beautifully.”
This is because in order for the AI Agent to actually carry out its work, it must reliably answer the following questions.
# Example structureWho is this customer?What is the status of this contract?What decision is this document based on?What team does this user belong to?What permissions does this action require?Under what conditions does this policy apply?Where should I record the results of this execution?RAG is strong at finding relevant document fragments. However, following objects and relationships in multiple systems and verifying status and permissions requires a separate structure.
At this time, the knowledge graph becomes the basis for connecting the organization's business objects.
7. Situations where ontology/KG is necessary and when it is excessive
Ontologies and knowledge graphs are powerful, but not necessary for every project.
It is worth introducing in the following situations:
| situation | why you need it | example |
|---|---|---|
| Different teams interpret the same object differently | Need a common semantic model | Customer, contract, approval, completion |
| Connect data from multiple systems | Entity consistency is required | CRM, ERP, Jira, Notion, Slack |
| Verification of permissions and policies is important | Condition checking required before execution | Contract changes, discount approvals, customer notifications |
| Need to track evidence | Requires provenance and audit logs | Reporting, decision making and compliance |
| Question crosses multiple objects | Relationship-based search is needed | Customer-Contract-Issue-Policy Connection |
| Multiple agents use the same organizational knowledge | Requires a shared semantic layer | Sales Agent, Operations Agent, Security Agent |
Conversely, it may be excessive in the following situations:
| situation | a simpler alternative |
|---|---|
| Single team internal affairs | Prompt Template + RAG |
| Single system inquiry/execution | API call + workflow |
| A person always gives final approval | Checklist + Log |
| Few terminological conflicts | Team Wiki + Tag System |
| The rules are simple | if/else policy variable |
| There is a lot to verify in the PoC stage | Check ROI with small automation first |
caution If you introduce ontology/KG as a “nice-to-have technology,” it is easy to fail. The criteria for adoption is not technology fads, but whether semantic inconsistencies, data linking, permission verification, and evidence tracking problems are actually repeated.
In practical terms, you can answer the following questions:
# Example structureDoes this work have conflicting terminology across multiple teams?Does this task require linking objects from multiple systems?Does this task require authorization and policy verification?Does this work require subsequent auditing of the basis for execution?Is there a high cost or risk if this task fails?The more “yes” there are, the greater the need for ontology and knowledge graphs.
8. Example: “Start onboarding new customers.”
Now let's look at a specific example.
The user makes this request to the AI Agent:
# Example structurePlease start onboarding Customer A.In the absence of an ontology and knowledge graph, Agents usually rely on document searches and prompts.
# Example structureSearch related documentsto Summary of onboarding processto create checklistto Send message to person in chargeFor simple team work, this may be enough.
But in organizational units, Agents need to see more.
# Example structureWhat kind of organization is Customer A?Is the contract status complete?Did you pass the security screening?Are there different procedures depending on the industry?Who is the responsible CSM?What version is the onboarding checklist?Is the requester authorized to initiate onboarding?What is the basis for the documents and actions created?In what system should the execution results be recorded?These questions are difficult to address reliably through simple document retrieval alone.
With ontology/KG, the flow changes.
# Example structureuser request↓Understand intent↓Interpreting business concepts with ontology↓Search related data with knowledge graph↓Permission/Policy/Status Verification↓Run the tools you need↓Record execution results and rationale back on the graphFor example, a graph might have the following connections:
# Example structureCustomer:A→ hasContract → Contract:B→ assignedTo → Person:CSM_C→ belongsToIndustry → Industry:Finance Contract:B→ hasStatus → Signed→ basedOn → Document:ContractDoc_D SecurityReview:E→ appliesTo → Customer:A→ hasStatus → Passed Action:StartOnboarding→ requiresPermission → Permission:OnboardingStart→ constrainedBy → Policy:FinanceCustomerOnboardingPolicyIn this way, the Agent can connect the sentence “Onboarding begins” with the actual work object of the organization.
In the end, the difference is this.
| method | movement | risk |
|---|---|---|
| Prompt/RAG centered | Find relevant documents and summarize procedures | Weak status, authority, and policy verification |
| Ontology/KG-centric | Search work objects and relationships and verify conditions | There are construction and operating costs |
Therefore, RAG and KG need not be viewed as competitors in organizational unit automation. RAG provides document context, KG provides business objects and relationships, and validation rules determine feasibility.
9. How to start with a small ontology
There is no need to create a transcription ontology from scratch. Rather, if you start that way, there is a high chance of failure.
A realistic sequence would be:
# Example structure1. Select one core task to automate2. Define the core questions of the work3. Extracting recurring concepts4. Create a minimal ontology5. Connect to existing DB/document/ticket/API6. Add validation rules7. Record agent execution logs and results8. Improve the model by analyzing failure logs9. Expand to other team workFor starters, the following models are sufficient:
# Example structureClass:- Project- Task- Document- Person- Team- System- Permission- Policy- Decision- Evidence- ActionRelationships can also start simple.
# Example structurePerson belongsTo TeamTask belongsTo ProjectTask requires DocumentDecision basedOn EvidenceAction executedBy AgentAction requires PermissionPolicy constrains ActionSystem owns DataEven with this level, AI Agent moves beyond a simple chatbot and becomes closer to “a system that understands the work status, checks conditions, leaves evidence, and executes.”
Practical Tips The goal of the first ontology is not to make it pretty. The goal is to leave behind only the concepts needed to reduce automation failures.
When starting small, the best baseline isCompetency Question. This is a way to first write down the question that this graph needs to answer.
For example:
# Example structureWhat is this customer's current contract status?Who can perform this action?What are the supporting documents for this decision?To which customer groups does this policy apply?What conditions are necessary for this task to be completed?As the question is determined, the required classes and relationships naturally decrease.
10. Practical checklist
If your organization is pursuing AI Agent automation, it is recommended that you first check the checklist below before introducing Ontology/KG.
# Example structureChecklist before application [ ] The core tasks to be automated have been narrowed down to one.[ ] Key objects that appear repeatedly in this work are organized.[ ] An issue where the same term was used differently by each team was identified.[ ] Data from multiple systems must be connected.[ ] Authorization or policy verification is required before execution.[ ] Documents supporting the results and audit logs are required.[ ] Failure is repeated with simple RAG and workflow.[ ] Domain experts can review the concept definition.[ ] Start with a small scope of work rather than a company-wide scope from the beginning.[ ] There are operational procedures to improve the ontology by looking at the failure log.If more than half of these apply, it is worth considering ontology and knowledge graph.
Conversely, if this is not the case for most of you, it may be better to start with RAG and workflow automation first.
11. Q&A
Q1. Do all AI Agents need an ontology?
no. It may be excessive for single team work, single system automation, and simple inquiry/summary tasks. It's a good idea to first check if your prompts, RAGs, tool calls, and checklists are sufficient.
Q2. If you use RAG, don’t you need a knowledge graph?
no. Their roles are different. RAG is strong at finding related document fragments, and knowledge graphs are strong at connecting objects and relationships. In organizational automation, the two are often used together.
Q3. Who should create the ontology?
Domain experts, AI/data engineers, and business managers must work together to create it. If only developers are created, the meaning of the work is lost, and if only actual businesses are created, it is difficult to create a workable structure.
Q4. Should I create a warrior KG first?
no. It's a good idea to start with one core task. For example, choose tasks with high repeatability and risk, such as customer onboarding, contract changes, failure response, and report publishing.
Q5. Do I need to move all existing DBs to Graph DB?
Not necessarily. It is also possible to leave the existing RDB, API, and document storage as is and add a semantic layer on top of it. The actual introduction strategy is covered in detail in Part 3.
12. References and uncertainty
References
- OpenAI, A practical guide to building agents
- Anthropic, Building Effective AI Agents
- W3C, OWL Web Ontology Language Overview
- W3C, OWL Web Ontology Language Use Cases and Requirements
- W3C, Shapes Constraint Language SHACL
confirmed facts
- Both OpenAI and Anthropic describe an approach to agent design that starts from simple, composable patterns, rather than forcing complex structures from scratch.
- W3C OWL is an ontology language that can express classes, properties, relationships, constraints, etc.
- SHACL is a standard for verifying that an RDF graph satisfies certain conditions.
Author's interpretation
- Ontology/KG is not an essential starting point for AI Agent, but is a necessary structure when semantic inconsistency and verification problems increase in organizational unit automation.
- The difference in operational risk between team-level automation and organization-level automation is greater than the difference in technology stack.
uncertainty
- Depending on the data structure, authority system, and business rules of each organization, the depth of ontology required can vary greatly.
- GraphRAG or KG based search is not always better than plain RAG. The effectiveness varies depending on the question type and data structure.
finish
To summarize, Ontology and knowledge graph are not necessarily required for AI Agent.
For individual or team automation, prompts, templates, RAGs, tool calls, and checklists are often sufficient.
But when you scale it up to organizational automation that connects multiple teams, multiple systems, and multiple rules, it's a different story. From this point on, rather than “AI that is good at finding documents,” “AI that consistently interprets the meaning of the organization’s work, verifies authority and rules, and leaves evidence” becomes necessary.
If you summarize it in one line, it is like this.
Ontology and Knowledge Graph are not the starting point of AI Agent, but semantic-based infrastructure to ensure scalability and reliability of AI automation at the organizational level.
In the next part, we will summarize the roles of Ontology, Knowledge Graph, RAG, GraphRAG, SHACL, and SPARQL from an architectural perspective.
summary card
- One-line summary: Ontology/KG is not a starting point for AI Agent, but a semantic-based infrastructure for organizational unit automation.
- Recommended for: Developers, AI TF, platform team, and CTO who want to expand AI automation from team to organizational level.
- Not recommended for: Single teams Internal summaries/searches/teams that only need simple tool calls
- The most important criteria: are semantic inconsistencies, authority verification, policy verification, and evidence tracking repeated?
- Biggest risk: losing the automation goal while trying to create an enterprise ontology from scratch.
- What to do right now: First, identify one core task you want to automate and the questions it needs to answer.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.